
kaggleIntrotoDeepLearningStochasticGradientDescent
Introduction
在前两课中,我们学习了如何通过堆叠密集层来构建全连接网络。网络在初始创建时,所有权重都是随机设置的——网络当时还“不知道”任何信息。在本课中,我们将学习如何训练神经网络;我们将了解神经网络如何“学习”。
与所有机器学习任务一样,我们从一组训练数据开始。训练数据中的每个示例都包含一些特征(输入)和一个预期目标(输出)。训练网络意味着调整其权重,使其能够将特征转化为目标。例如,在“80 种谷物”数据集中,我们希望网络能够获取每种谷物的“糖”、“纤维”和“蛋白质”含量,并预测该谷物的“卡路里”。如果我们能够成功地训练一个网络来实现这一点,那么它的权重必须以某种方式表示这些特征与训练数据中所表达的目标之间的关系。
除了训练数据,我们还需要两样东西:
- 一个“损失函数”,用于衡量网络预测的准确性。
- 一个“优化器”,用于指导网络如何调整其权重。
The Loss Function
我们已经了解了如何设计网络架构,但尚未了解如何告诉网络要解决什么问题。这就是损失函数的作用。
损失函数衡量目标真实值与模型预测值之间的差异。
不同的问题需要不同的损失函数。我们一直在研究回归问题,其任务是预测一些数值,例如80%谷物的卡路里含量,红酒品质的评级。其他回归任务可能是预测房价或汽车的燃油效率。
回归问题的常见损失函数是平均绝对误差或MAE。对于每个预测值“y_pred”,MAE 衡量与真实目标值“y_true”之间的绝对差值“abs(y_true - y_pred)”。
数据集上的总 MAE 损失是所有这些绝对差值的平均值。
 平均绝对误差是拟合曲线与数据点之间的平均长度。
平均绝对误差是拟合曲线与数据点之间的平均长度。
除了 MAE 之外,您可能在回归问题中看到的其他损失函数是均方误差 (MSE) 或 Huber 损失(两者均可在 Keras 中使用)。
在训练过程中,模型将使用损失函数作为指导,找到其权重的正确值(损失越低越好)。换句话说,损失函数告诉网络它的目标。
The Optimizer - Stochastic Gradient Descent
我们已经描述了我们希望网络解决的问题,现在我们需要说明如何解决它。这就是优化器的工作。优化器是一种调整权重以最小化损失的算法。
深度学习中使用的几乎所有优化算法都属于随机梯度下降家族。它们是逐步训练网络的迭代算法。训练的一个步骤如下:
- 采样一些训练数据,并在网络中运行以进行预测。
- 测量预测值与真实值之间的损失。
- 最后,朝着使损失更小的方向调整权重。
然后反复执行此操作,直到损失达到您想要的最小值(或直到它不再减少)。
使用随机梯度下降法训练神经网络。
每次迭代的训练数据样本称为小批次(通常简称为“批次”),而一轮完整的训练数据称为迭代次数。训练的迭代次数是指网络对每个训练样本进行训练的次数。
动画展示了使用随机梯度下降法 (SGD) 训练第一课中的线性模型。浅红色圆点代表整个训练集,实心红色圆点代表小批次。每次随机梯度下降法 (SGD) 遇到新的小批次时,它都会将权重(“w” 表示斜率,“b” 表示 y 轴截距)向该批次的正确值移动。经过一个批次的训练,这条线最终会收敛到最佳拟合值。您可以看到,随着权重越来越接近其真实值,损失值也越来越小。
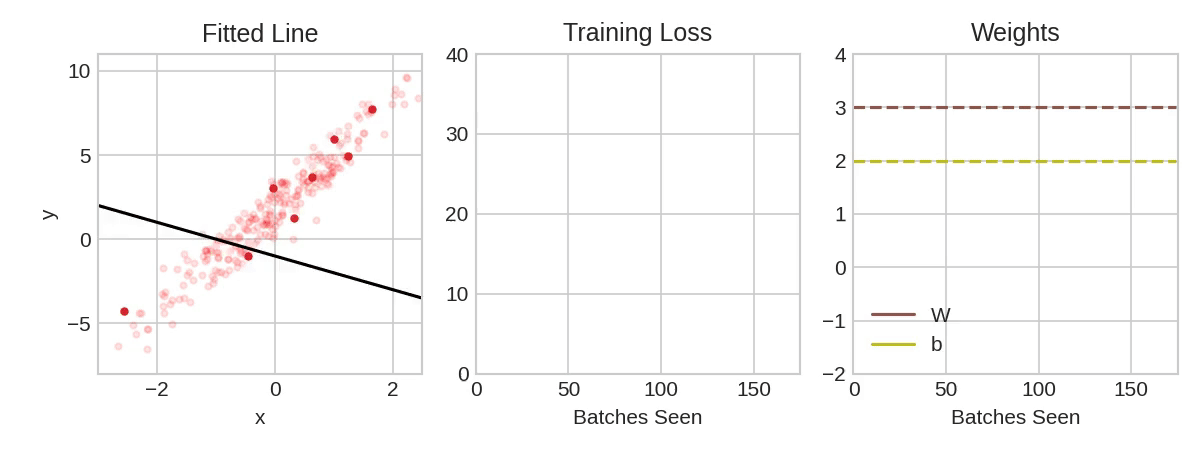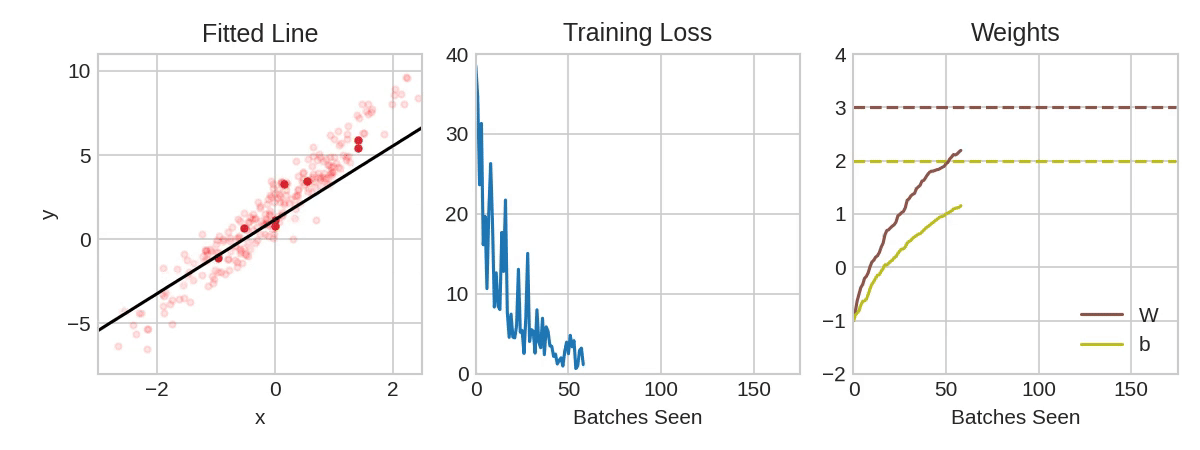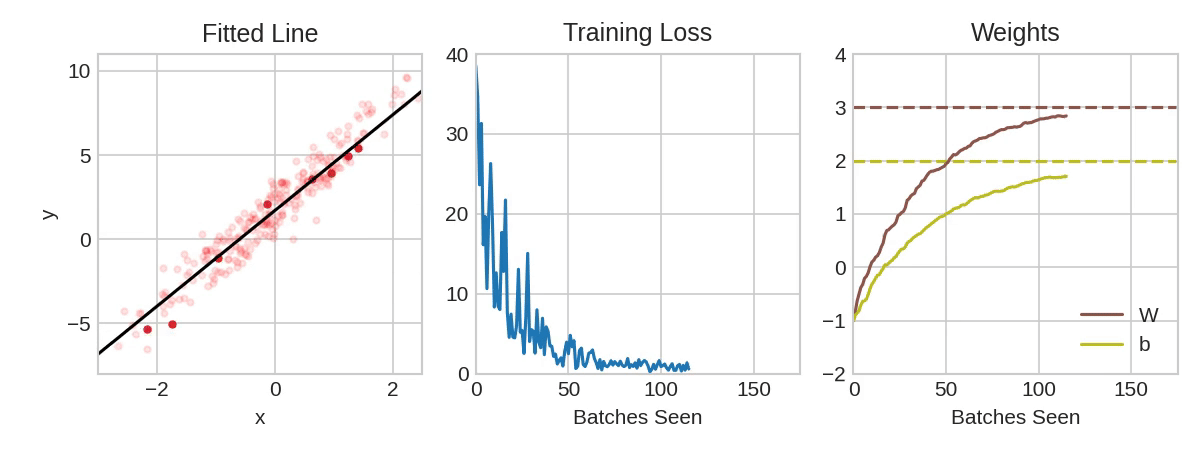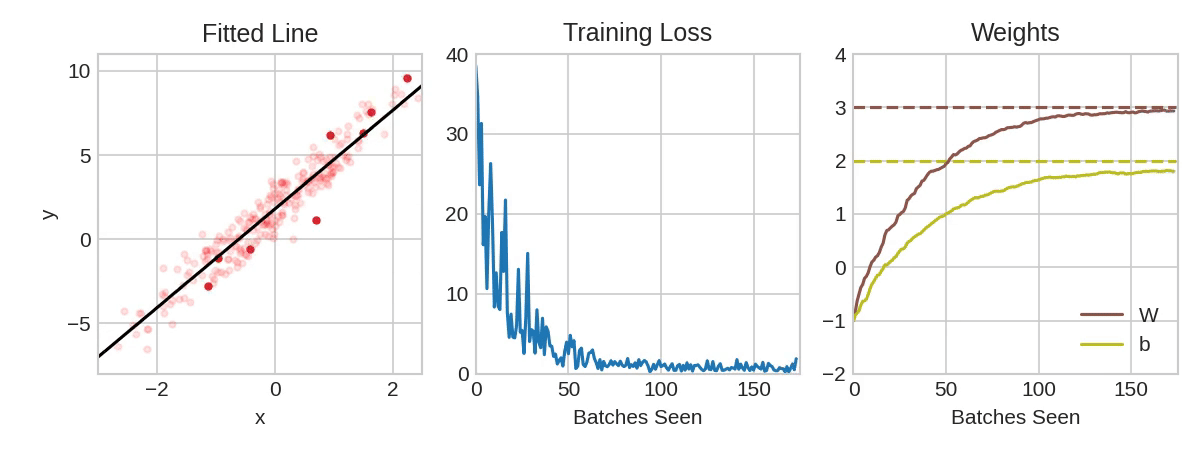
Learning Rate and Batch Size
请注意,这条线只会在每个批次的方向上进行微小的移动(而不是完全移动)。这些移动的大小由学习率决定。较小的学习率意味着网络需要学习更多的小批次才能使其权重收敛到最佳值。
学习率和小批次的大小是影响随机梯度下降 (SGD) 训练过程的两个最大参数。它们之间的相互作用通常很微妙,而且这些参数的正确选择并不总是显而易见的。(我们将在练习中探讨这些影响。)
幸运的是,对于大多数工作来说,无需进行广泛的超参数搜索即可获得满意的结果。Adam 是一种具有自适应学习率的随机梯度下降 (SGD) 算法,这使得它适用于大多数问题,而无需任何参数调整(从某种意义上说,它是“自调整”的)。Adam 是一个优秀的通用优化器。
Adding the Loss and Optimizer
定义模型后,可以使用模型的“compile”方法添加损失函数和优化器:
model.compile( |
请注意,我们只需一个字符串即可指定损失函数和优化器。您也可以直接通过 Keras API 访问这些参数(例如,如果您想调整参数),但对于我们来说,默认设置就足够了。
名称含义
梯度是一个向量,它告诉我们权重需要朝哪个方向变化。更准确地说,它告诉我们如何调整权重才能使损失变化最快。我们将这个过程称为梯度下降,因为它使用梯度使损失曲线下降至最小值。随机的意思是“由偶然决定”。我们的训练是随机的,因为小批量是从数据集中随机抽取的样本。这就是它被称为SGD的原因!
Example - Red Wine Quality
现在我们已经了解了开始训练深度学习模型所需的一切。让我们来看看它的实际效果!我们将使用“红酒品质”数据集。
该数据集包含约 1600 款葡萄牙红酒的理化测量数据。此外,还包含每种葡萄酒的盲品评级。我们能根据这些测量数据预测葡萄酒的感知品质吗?
我们将所有数据准备工作都放在了下一个隐藏单元中。它对后续内容并非必需,因此您可以跳过它。不过,您现在可能需要注意的是,我们已将每个特征重新缩放至 [0,1] 区间。正如我们将在第 5 课中进一步讨论的那样,当输入处于共同的尺度时,神经网络往往表现最佳。
import pandas as pd |
| fixed acidity | volatile acidity | citric acid | residual sugar | chlorides | free sulfur dioxide | total sulfur dioxide | density | pH | sulphates | alcohol | quality | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1109 | 10.8 | 0.470 | 0.43 | 2.10 | 0.171 | 27.0 | 66.0 | 0.99820 | 3.17 | 0.76 | 10.8 | 6 |
| 1032 | 8.1 | 0.820 | 0.00 | 4.10 | 0.095 | 5.0 | 14.0 | 0.99854 | 3.36 | 0.53 | 9.6 | 5 |
| 1002 | 9.1 | 0.290 | 0.33 | 2.05 | 0.063 | 13.0 | 27.0 | 0.99516 | 3.26 | 0.84 | 11.7 | 7 |
| 487 | 10.2 | 0.645 | 0.36 | 1.80 | 0.053 | 5.0 | 14.0 | 0.99820 | 3.17 | 0.42 | 10.0 | 6 |
这个网络应该有多少个输入?我们可以通过查看数据矩阵的列数来发现这一点。请确保这里不要包含目标(“质量”)——只包含输入特征。
print(X_train.shape) |
十一列意味着十一个输入。
我们选择了一个包含超过 1500 个神经元的三层网络。该网络应该能够学习数据中相当复杂的关系。
from tensorflow import keras |
确定模型架构应该是一个完整的过程。从简单的开始,并使用验证损失作为指导。您将在练习中了解更多关于模型开发的知识。
定义模型后,我们将编译优化器和损失函数。
model.compile( |
现在我们准备开始训练了!我们已经告诉 Keras 每次向优化器提供 256 行训练数据(“batch_size”),并在数据集中重复 10 次(“epochs”)。
history = model.fit( |
您可以看到,Keras 会在模型训练过程中持续更新损失。
通常,查看损失的更好方法是绘制图表。“fit”方法实际上会将训练期间产生的损失记录在“History”对象中。我们将数据转换为 Pandas DataFrame,以便于绘制图表。
import pandas as pd |

注意损失是如何随着迭代次数的增加而趋于平稳的。当损失曲线变得像那样水平时,意味着模型已经学到了所有能学到的东西,没有必要继续进行额外的迭代次数。