
kaggleIntrotoDeepLearningOverfittingandUnderfitting
Introduction
回想一下上一课中的示例,Keras 会保存模型训练过程中各个时期的训练和验证损失历史记录。在本课中,我们将学习如何解读这些学习曲线,以及如何利用它们来指导模型开发。具体来说,我们将分析学习曲线中是否存在“欠拟合”和“过拟合”的证据,并探讨一些纠正策略。
Interpreting the Learning Curves
验证损失是对未见数据的预期误差的估计。
现在,无论是当模型学习信号还是学习噪声时,训练损失都会下降。但只有当模型学习信号时,验证损失才会下降。(模型从训练集学习到的任何噪声都不会推广到新数据。)因此,当模型学习信号时,两条曲线都会下降,但当模型学习噪声时,曲线中就会出现一个“缺口”。缺口的大小表明模型学习了多少噪声。
理想情况下,我们应该创建学习所有信号而不学习任何噪声的模型。但这几乎永远不会发生。相反,我们会进行权衡。我们可以让模型学习更多信号,代价是学习更多噪声。只要这种权衡对我们有利,验证损失就会持续下降。然而,在某个点之后,这种权衡可能会对我们不利,成本超过收益,验证损失就会开始上升。
 现在,无论是当模型学习信号还是学习噪声时,训练损失都会下降。但只有当模型学习信号时,验证损失才会下降。(模型从训练集学习到的任何噪声都不会推广到新数据。)因此,当模型学习信号时,两条曲线都会下降,但当它学习噪声时,曲线上就会出现一个缺口。缺口的大小表明模型学习了多少噪声。
现在,无论是当模型学习信号还是学习噪声时,训练损失都会下降。但只有当模型学习信号时,验证损失才会下降。(模型从训练集学习到的任何噪声都不会推广到新数据。)因此,当模型学习信号时,两条曲线都会下降,但当它学习噪声时,曲线上就会出现一个缺口。缺口的大小表明模型学习了多少噪声。
理想情况下,我们应该创建能够学习所有信号而不学习任何噪声的模型。但这几乎永远不会发生。相反,我们会进行权衡。我们可以让模型学习更多信号,代价是学习更多噪声。只要这种权衡对我们有利,验证损失就会持续下降。然而,在某个点之后,这种权衡可能会对我们不利,成本超过收益,验证损失就会开始上升。
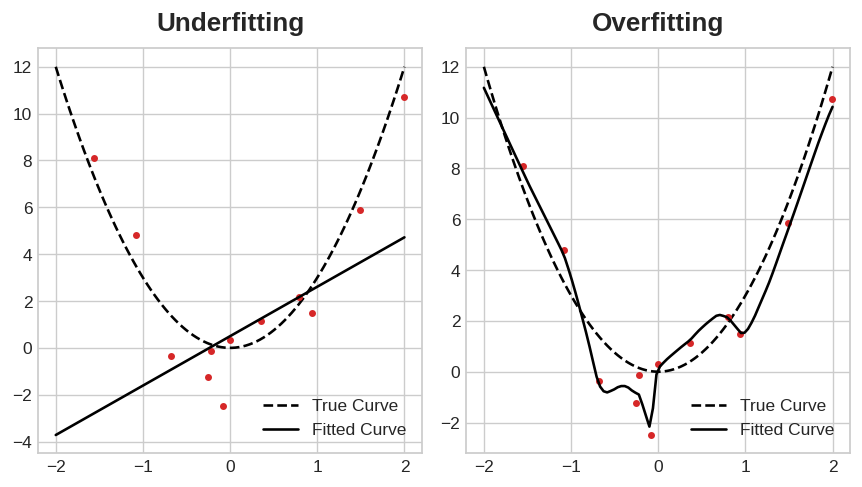
欠拟合与过拟合。
这种权衡表明,在训练模型时可能出现两个问题:信号不足或噪声过多。训练集的欠拟合是指由于模型没有学习到足够的信号,导致损失没有达到应有的水平。训练集的过拟合是指由于模型学习到过多的噪声,导致损失没有达到应有的水平。训练深度学习模型的诀窍在于找到两者之间的最佳平衡。
我们将介绍几种从训练数据中获取更多信号并减少噪声的方法。
Capacity
模型的容量指的是它能够学习的模式的大小和复杂度。对于神经网络来说,这很大程度上取决于它有多少个神经元以及它们是如何连接的。如果你的网络看起来与数据不拟合,你应该尝试增加它的容量。
你可以通过增加网络的宽度(在现有层中添加更多单元)或深度(添加更多层)来增加网络的容量。更宽的网络更容易学习线性关系,而更深的网络则更容易学习非线性关系。哪种方式更好取决于数据集。
model = keras.Sequential([ |
您将探索网络容量如何影响其在练习中的性能。
Early Stopping
我们提到过,当模型过于热衷于学习噪声时,验证损失可能会在训练过程中开始增加。为了防止这种情况,我们可以在验证损失似乎不再减少时停止训练。这种中断训练的方式称为提前停止。
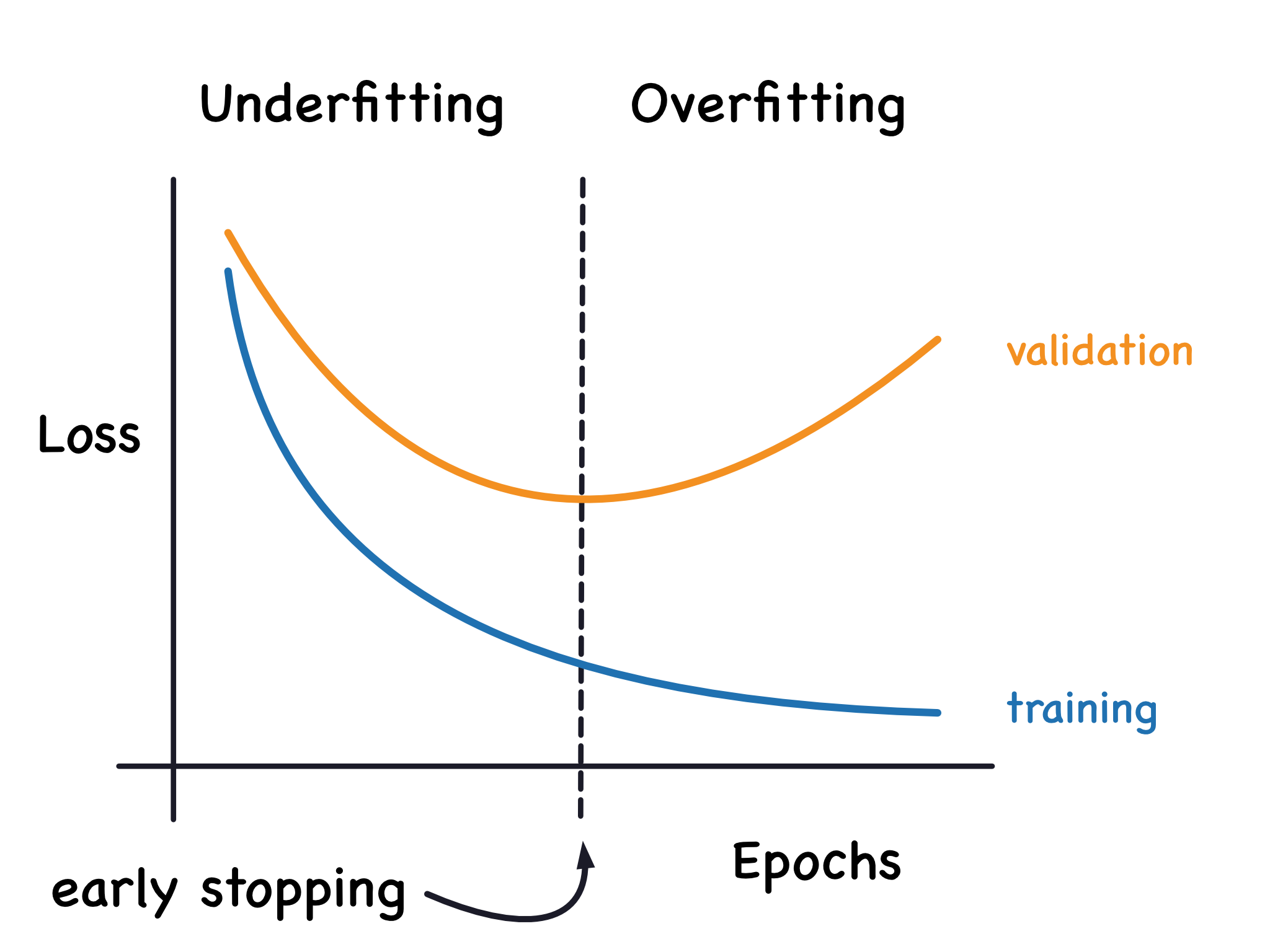
我们保持模型验证损失最小。
一旦检测到验证损失再次开始上升,我们就将权重重置回最小值出现的位置。这确保了模型不会继续学习噪声并导致数据过拟合。
使用提前停止进行训练还意味着我们不太可能在网络完成信号学习之前就过早停止训练。因此,除了防止因训练时间过长而导致过拟合之外,提前停止还可以防止因训练时间不足而导致的欠拟合。只需将训练周期设置为较大的数字(大于所需的周期),提前停止将处理剩下的事情。
Adding Early Stopping
在 Keras 中,我们通过回调函数在训练过程中实现提前停止。回调函数就是你在网络训练过程中希望经常运行的一个函数。提前停止回调函数会在每次迭代后运行。(Keras 预定义了各种实用的回调函数,但你也可以自定义。)
from tensorflow.keras.callbacks import EarlyStopping |
这些参数表示:“如果在过去 20 个周期内,验证损失没有至少 0.001 的改善,则停止训练并保留你找到的最佳模型。” 有时很难判断验证损失的上升是由于过拟合还是仅仅是由于随机批次变化造成的。这些参数允许我们设置一些关于何时停止的余地。
正如我们在示例中看到的,我们将此回调与损失和优化器一起传递给 fit 方法。
Example - Train a Model with Early Stopping
让我们继续开发上一个教程中的示例模型。我们将增加该网络的容量,并添加一个提前停止回调以防止过拟合。
以下是数据准备部分。
import pandas as pd |
| fixed acidity | volatile acidity | citric acid | residual sugar | chlorides | free sulfur dioxide | total sulfur dioxide | density | pH | sulphates | alcohol | quality | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1109 | 10.8 | 0.470 | 0.43 | 2.10 | 0.171 | 27.0 | 66.0 | 0.99820 | 3.17 | 0.76 | 10.8 | 6 |
| 1032 | 8.1 | 0.820 | 0.00 | 4.10 | 0.095 | 5.0 | 14.0 | 0.99854 | 3.36 | 0.53 | 9.6 | 5 |
| 1002 | 9.1 | 0.290 | 0.33 | 2.05 | 0.063 | 13.0 | 27.0 | 0.99516 | 3.26 | 0.84 | 11.7 | 7 |
| 487 | 10.2 | 0.645 | 0.36 | 1.80 | 0.053 | 5.0 | 14.0 | 0.99820 | 3.17 | 0.42 | 10.0 | 6 |
现在让我们增加网络的容量。我们将选择一个相当大的网络,但一旦验证损失出现增加的迹象,就依靠回调来停止训练。
from tensorflow import keras |
定义回调函数后,将其作为参数添加到 fit 中(你可以有多个参数,因此请将其放在列表中)。使用提前停止时,请选择比实际需要更多的 epoch 数。
history = model.fit( |

果然,Keras 在完成 500 个 epoch 之前就停止了训练!·