
kaggleIntrotoDeepLearningDropoutandBatchNormalization
Introduction
深度学习的世界远不止密集层。你可以为模型添加数十种类型的层。(不妨浏览 Keras 文档 获取示例!)有些层类似于密集层,用于定义神经元之间的连接;有些层可以进行预处理或其他类型的转换。
在本课中,我们将学习两种特殊的层,它们本身不包含任何神经元,但会添加一些功能,有时可以通过多种方式使模型受益。这两种层在现代架构中都很常用。
Dropout
第一个是“dropout 层”,它可以帮助纠正过拟合。
在上一课中,我们讨论了网络在训练数据中学习虚假模式是如何导致过拟合的。为了识别这些虚假模式,网络通常会依赖于非常具体的权重组合,这是一种权重的“阴谋”。由于过于具体,这些组合往往很脆弱:移除一个,这种阴谋就会瓦解。
这就是 dropout 背后的想法。为了打破这些阴谋,我们在训练的每一步随机地“丢弃”一部分层输入单元,这使得网络更难在训练数据中学习这些虚假模式。相反,它必须搜索更广泛的、通用的模式,这些模式的权重模式往往更稳健。
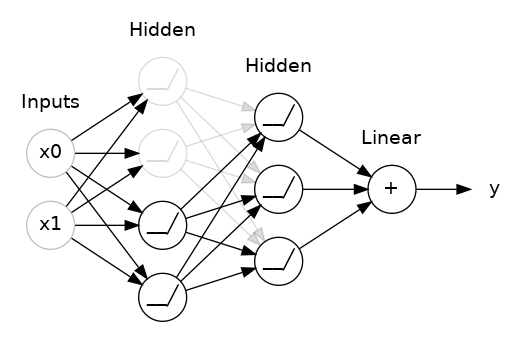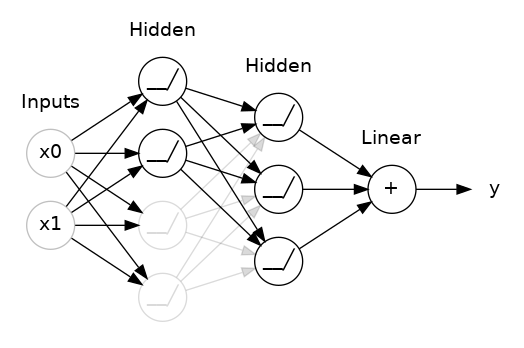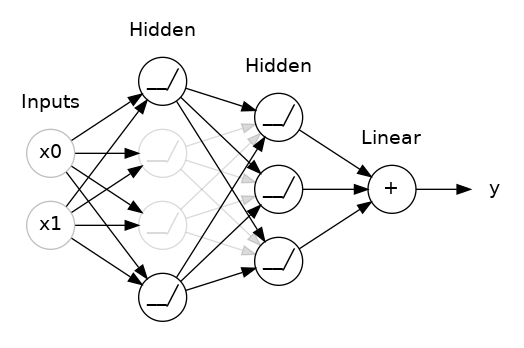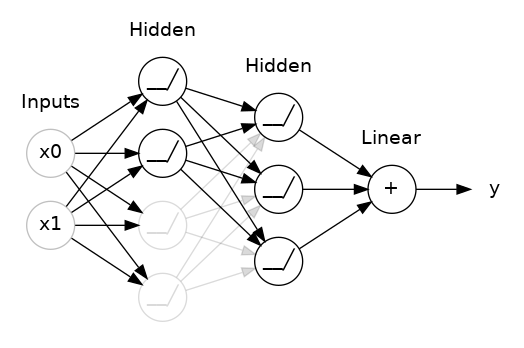 这里,两个隐藏层之间添加了 50% 的 Dropout。
这里,两个隐藏层之间添加了 50% 的 Dropout。
您也可以将 Dropout 视为创建一种网络集成。预测将不再由一个大型网络进行,而是由一个由多个小型网络组成的委员会进行。委员会中的个人往往会犯不同类型的错误,但同时又能做出正确的判断,这使得委员会作为一个整体比任何个人都更优秀。(如果您熟悉随机森林作为决策树的集成,那么两者的思路是一样的。)
Adding Dropout
在 Keras 中,dropout 率参数 rate 定义了要关闭的输入单元的百分比。将 Dropout 层放在要应用 dropout 的层之前:
keras.Sequential([ |
Batch Normalization
我们将要讨论的下一个特殊层执行“批量归一化”(或“batchnorm”),它可以帮助纠正缓慢或不稳定的训练。
对于神经网络,通常最好将所有数据放在一个通用的尺度上,例如使用 scikit-learn 的 StandardScaler 或 MinMaxScaler。原因是 SGD 会根据数据产生的激活值的大小按比例移动网络权重。那些倾向于产生大小差异很大的激活值的特征可能会导致训练行为不稳定。
现在,如果在数据进入网络之前对其进行归一化是好的,那么在网络内部进行归一化可能更好!事实上,我们有一种特殊的层可以做到这一点,那就是批量归一化层。批量归一化层会处理每个传入的批次,首先用其自身的均值和标准差对批次进行归一化,然后使用两个可训练的缩放参数将数据放到一个新的尺度上。批量归一化实际上对输入执行了一种协调的缩放。
批量归一化通常作为优化过程的辅助手段添加(尽管有时它也能提高预测性能)。采用批量归一化的模型通常需要更少的训练周期来完成训练。此外,批量归一化还可以解决各种可能导致训练“卡住”的问题。考虑将批量归一化添加到您的模型中,尤其是在训练过程中遇到困难时。
Adding Batch Normalization
看来批量归一化几乎可以在网络的任何位置使用。你可以把它放在某一层之后……
layers.Dense(16, activation='relu'), |
… 或者在层和它的激活函数之间:
layers.Dense(16), |
如果您将其添加为网络的第一层,它可以充当一种自适应预处理器,代替 Sci-Kit Learn 的“StandardScaler”之类的东西。
Example - Using Dropout and Batch Normalization
让我们继续开发“红酒”模型。现在我们将进一步提升容量,并添加dropout来控制过拟合,以及批量归一化来加速优化。这次,我们将不再进行数据标准化,以演示批量归一化如何稳定训练。
# Setup plotting |
添加 dropout 时,您可能需要增加“Dense”层中的单元数量。
from tensorflow import keras |
这次我们的训练安排没有任何改变。
model.compile( |
通常,在使用数据进行训练之前对其进行标准化会获得更好的性能。然而,我们能够使用原始数据,这证明了批量标准化在更复杂的数据集上是多么有效。