
kaggleIntermediateMachineLearningCross-Validation
Introduction
机器学习是一个迭代过程。
您将面临关于使用哪些预测变量、使用哪些类型的模型、为这些模型提供哪些参数等的选择。到目前为止,您已经通过使用验证集(或保留集)来衡量模型质量,以数据驱动的方式做出了这些选择。
但这种方法存在一些缺点。为了说明这一点,假设您有一个包含 5000 行数据的数据集。您通常会保留大约 20% 的数据作为验证数据集,即 1000 行。但这会在确定模型得分时留下一些随机因素。也就是说,一个模型可能在一个包含 1000 行的数据集上表现良好,即使在另一个包含 1000 行的数据集上可能不准确。
在极端情况下,您可以想象验证集中只有一行数据。如果您比较不同的模型,那么哪个模型对单个数据点的预测结果最佳,很大程度上取决于运气!
一般来说,验证集越大,我们衡量模型质量的随机性(也就是“噪声”)就越小,模型就越可靠。可惜的是,我们只能通过从训练数据中删除行来获得更大的验证集,而训练数据集越小,模型就越差!
What is cross-validation?
在交叉验证中,我们会对数据的不同子集运行建模流程,以获得多种模型质量指标。
例如,我们可以先将数据分成 5 份,每份占整个数据集的 20%。在这种情况下,我们称数据被分成了 5 个“折叠”。
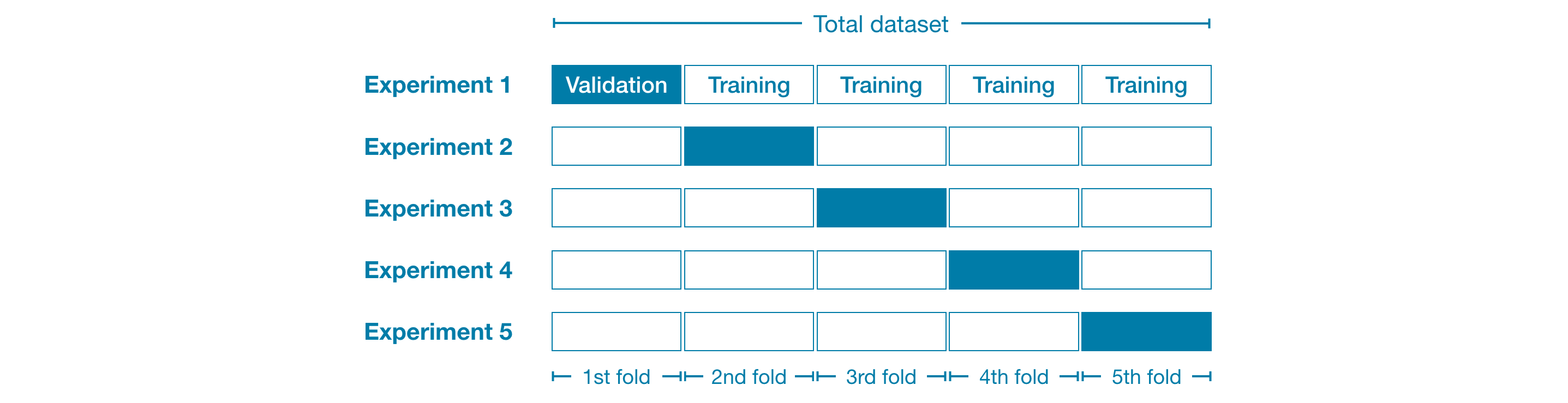
然后,我们对每个折叠进行一次实验:
- 在实验 1 中,我们使用第一个折叠作为验证集(或保留集),其余所有数据作为训练数据。这样,我们就可以根据 20% 保留集来衡量模型质量。
- 在实验 2 中,我们保留第二个折叠的数据(并使用除第二个折叠之外的所有数据来训练模型)。然后,使用保留集对模型质量进行第二次评估。
- 我们重复此过程,每个折叠都使用一次作为保留集。总而言之,在某个时刻,100% 的数据都会被用作保留集,最终我们得到一个基于数据集所有行(即使我们不会同时使用所有行)的模型质量衡量指标。
When should you use cross-validation?
交叉验证可以更准确地衡量模型质量,这在您进行大量建模决策时尤为重要。但是,由于它会估算多个模型(每个折叠一个模型),因此运行时间可能会更长。
那么,考虑到这些权衡利弊,您应该何时使用每种方法呢?
- 对于小型数据集,额外的计算负担并不大,您应该运行交叉验证。
- 对于大型数据集,单个验证集就足够了。您的代码运行速度会更快,而且您可能拥有足够的数据,几乎不需要重复使用其中一部分数据进行留存。
对于大型数据集和小型数据集,并没有简单的阈值。但是,如果您的模型运行时间只需几分钟或更短,那么切换到交叉验证可能是值得的。
或者,您可以运行交叉验证,看看每个实验的得分是否接近。如果每个实验的结果相同,那么单个验证集可能就足够了。
Example
我们将使用与上一教程相同的数据。我们将输入数据加载到“X”中,并将输出数据加载到“y”中。
然后,我们定义一个管道,使用插补器填充缺失值,并使用随机森林模型进行预测。
虽然不使用管道也可以进行交叉验证,但这相当困难!使用管道会使代码变得非常简单。
from sklearn.ensemble import RandomForestRegressor |
我们使用 scikit-learn 中的 cross_val_score() 函数获取交叉验证分数。我们使用 cv 参数设置折叠次数。
from sklearn.model_selection import cross_val_score |
scoring 参数用于选择要报告的模型质量指标:在本例中,我们选择了负平均绝对误差 (MAE)。scikit-learn 的文档展示了一个选项列表。
我们指定了 负 MAE 有点令人惊讶。Scikit-learn 有一个惯例,即所有指标都已定义,因此数值越大越好。在这里使用负值可以使它们与该惯例保持一致,尽管负 MAE 在其他地方几乎闻所未闻。
我们通常需要一个单一的模型质量指标来比较不同的模型。因此,我们取所有实验的平均值。
print("Average MAE score (across experiments):") |
Conclusion
使用交叉验证可以更好地衡量模型质量,同时还能简化代码:请注意,我们不再需要分别跟踪训练集和验证集。因此,对于小型数据集而言,这无疑是一项重大改进!