import pandas as pd from sklearn.model_selection import train_test_split
# Load the data data = pd.read_csv('../input/melbourne-housing-snapshot/melb_data.csv')
# Select target y = data.Price
# To keep things simple, we'll use only numerical predictors melb_predictors = data.drop(['Price'], axis=1) X = melb_predictors.select_dtypes(exclude=['object'])
# Divide data into training and validation subsets X_train, X_valid, y_train, y_valid = train_test_split(X, y, train_size=0.8, test_size=0.2, random_state=0)
from sklearn.ensemble import RandomForestRegressor from sklearn.metrics import mean_absolute_error
# Function for comparing different approaches defscore_dataset(X_train, X_valid, y_train, y_valid): model = RandomForestRegressor(n_estimators=10, random_state=0) model.fit(X_train, y_train) preds = model.predict(X_valid) return mean_absolute_error(y_valid, preds)
方法 1 的得分(删除缺失值的列)
由于我们同时处理训练集和验证集,因此我们会小心地在两个 DataFrame 中删除相同的列。
In [3]:
# Get names of columns with missing values cols_with_missing = [col for col in X_train.columns if X_train[col].isnull().any()]
# Drop columns in training and validation data reduced_X_train = X_train.drop(cols_with_missing, axis=1) reduced_X_valid = X_valid.drop(cols_with_missing, axis=1)
print("MAE from Approach 1 (Drop columns with missing values):") print(score_dataset(reduced_X_train, reduced_X_valid, y_train, y_valid)) MAE from Approach 1 (Drop columns with missing values): 183550.22137772635
# Imputation removed column names; put them back imputed_X_train.columns = X_train.columns imputed_X_valid.columns = X_valid.columns
print("MAE from Approach 2 (Imputation):") print(score_dataset(imputed_X_train, imputed_X_valid, y_train, y_valid)) MAE from Approach 2 (Imputation): 178166.46269899711
我们发现方法 2 的 MAE 低于方法 1,因此方法 2 在该数据集上表现更佳。
方法 3 的得分(插补的扩展)
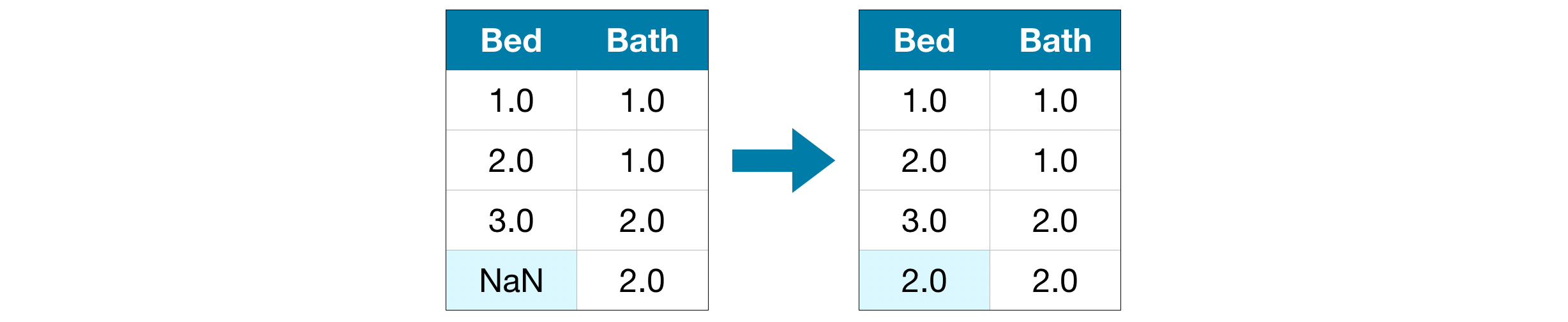
接下来,我们插补缺失值,同时跟踪哪些值被插补。
In [5]:
# Make copy to avoid changing original data (when imputing) X_train_plus = X_train.copy() X_valid_plus = X_valid.copy()
# Make new columns indicating what will be imputed for col in cols_with_missing: X_train_plus[col + '_was_missing'] = X_train_plus[col].isnull() X_valid_plus[col + '_was_missing'] = X_valid_plus[col].isnull()
# Imputation removed column names; put them back imputed_X_train_plus.columns = X_train_plus.columns imputed_X_valid_plus.columns = X_valid_plus.columns
print("MAE from Approach 3 (An Extension to Imputation):") print(score_dataset(imputed_X_train_plus, imputed_X_valid_plus, y_train, y_valid)) MAE from Approach 3 (An Extension to Imputation): 178927.503183954
# Shape of training data (num_rows, num_columns) print(X_train.shape)
# Number of missing values in each column of training data missing_val_count_by_column = (X_train.isnull().sum()) print(missing_val_count_by_column[missing_val_count_by_column > 0]) (10864, 12) Car 49 BuildingArea 5156 YearBuilt 4307 dtype: int64