
kaggleIntrotoMachineLearning欠拟合和过拟合
完成本步骤后,您将理解欠拟合和过拟合的概念,并能够运用这些概念来提升模型的准确性。
Underfitting and Overfitting
现在您已经掌握了可靠的方法来衡量模型的准确性,您可以尝试不同的模型,看看哪个模型的预测效果最佳。但是,您有哪些其他的模型呢?
您可以在 scikit-learn 的文档中看到,决策树模型有很多选项(比您长期所需的选项还要多)。最重要的选项决定了树的深度。回想一下本课程的第一课,树的深度衡量的是它在做出预测之前进行了多少次分裂。这是一棵相对较浅的树。
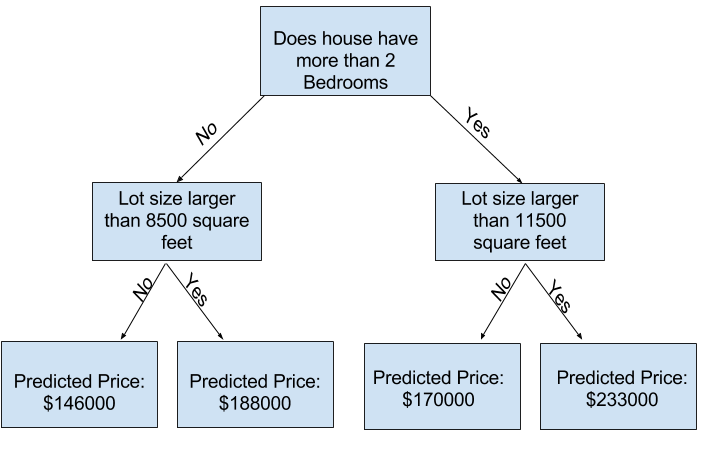
实践中,一棵树在顶层(所有房屋)和一片叶子节点之间进行 10 次分割的情况并不少见。随着树的深度增加,数据集会被切分成包含较少房屋的叶子节点。如果一棵树只有 1 次分割,它会将数据分成 2 组。如果每组再次分割,我们会得到 4 组房屋。再次分割每组房屋将创建 8 组。如果我们通过在每一层增加更多分割来使房屋组数量翻倍,那么到第十层时,我们将拥有 210210 组房屋。也就是 1024 片叶子节点。
当我们将房屋划分到许多叶子节点时,每片叶子节点上的房屋数量也会减少。房屋数量很少的叶子节点的预测结果会非常接近这些房屋的实际价值,但它们对新数据的预测结果可能非常不可靠(因为每个预测都仅基于少数房屋)。
这种现象称为过拟合,即模型几乎完美地匹配训练数据,但在验证集和其他新数据中表现不佳。另一方面,如果我们的树结构非常浅,它就无法将房屋划分成截然不同的组。
在极端情况下,如果一棵树只将房屋分成 2 或 4 组,那么每组中仍然包含各种各样的房屋。即使在训练数据中,最终的预测结果也可能与大多数房屋的预测结果相差甚远(出于同样的原因,它在验证集上的表现也会很差)。当模型无法捕捉数据中的重要特征和模式,以至于即使在训练数据中也表现不佳时,这种情况称为欠拟合。
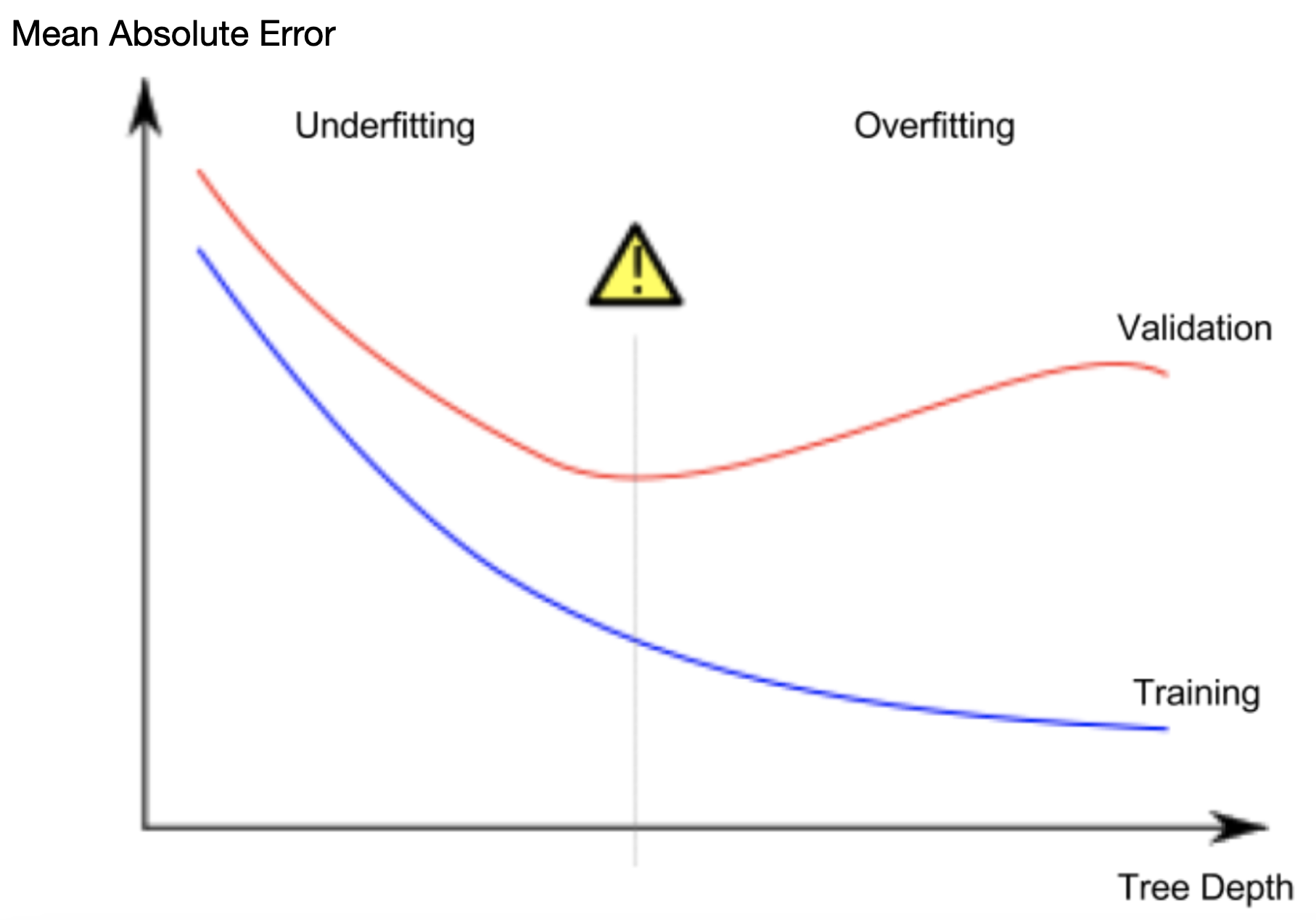
由于我们关心新数据的准确性(我们根据验证集估算),因此我们希望找到欠拟合和过拟合之间的最佳平衡点。直观地讲,我们希望下图中(红色)验证曲线的最低点。
Example
控制树的深度有几种方法,其中许多方法允许某些路径比其他路径具有更大的深度。但 max_leaf_nodes 参数提供了一种非常合理的方法来控制过拟合和欠拟合。我们允许模型生成的叶子节点越多,我们就越能从上图中的欠拟合区域移向过拟合区域。
我们可以使用一个效用函数来比较不同 max_leaf_nodes 值的 MAE 得分:
In [1]:
from sklearn.metrics import mean_absolute_error |
使用您已经看到的代码(以及您已经编写的代码)将数据加载到train_X、val_X、train_y 和 val_y 中。
# Data Loading Code Runs At This Point |
我们可以使用 for 循环来比较使用不同 max_leaf_nodes 值构建的模型的准确性。
# compare MAE with differing values of max_leaf_nodes |
Max leaf nodes: 5 Mean Absolute Error: 347380 |
在列出的选项中,500 是最佳叶子数量。
Conclusion
要点如下:模型可能会遇到以下两种情况:
- 过拟合:捕获未来不会重复出现的虚假模式,导致预测精度降低
- 欠拟合:未能捕获相关模式,同样导致预测精度降低。
我们使用验证数据(模型训练中不会使用)来衡量候选模型的精度。这使我们能够尝试多个候选模型,并保留最佳模型。
Your Turn
尝试**优化你之前构建的模型**。