
IntroToAssemblyBasicInstructionsANDFunctionsHTB
Module Project
到目前为止,我们已经学习了计算机和CPU架构的基础知识以及汇编语言和调试的基础知识。我们现在开始学习各种x86汇编指令。我们很可能在渗透测试和逆向工程练习中遇到这些类型的指令,因此了解它们的工作方式使我们能够解释它们在做什么,并了解程序在做什么。
我们将从学习如何在寄存器和内存地址之间移动数据和值开始。然后,我们将学习使用一个操作数的指令(Unary Operations)和使用两个操作数的指令(Binary Instructions)。稍后,我们将学习汇编控制指令和shellcoding。
斐波那契数列
然而,在我们开始之前,让我们讨论一下我们将在本模块中使用我们将学习的各种指令开发的程序。
We will be developing a basic Fibonacci sequence calculator using x86 assembly language.
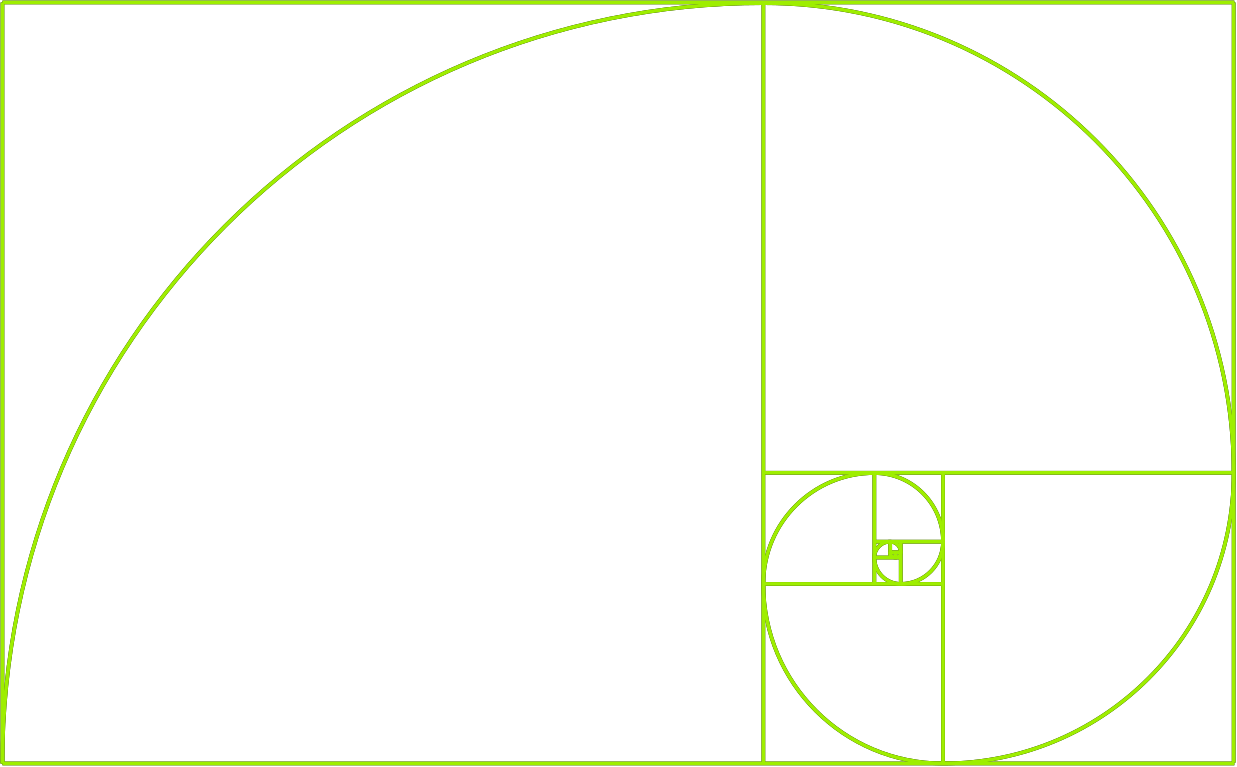
在最简单的术语中,斐波那契数是序列中它前面的两个数字的总和(即Fn = Fn-1 + Fn-2)。例如,如果我们从F0=0和F1=1开始,那么F2是F1 + F0,也就是F2 = 1 + 0 -> 1。
根据同样的公式,F3是F3=1+1=2,F4是F4 = 2 + 1 -> 3,依此类推。
如果我们继续到F10,这是我们的序列:0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55。正如我们所看到的,每个数字都等于它前面两个数字的总和。
黄金比例
斐波那契数列在许多领域都很方便,如艺术、数学、物理、计算机科学,甚至经济和金融。例如,斐波那契数列是黄金比例(or phi Φ)的一个很好的代表,它被历史上许多艺术家和建筑师使用,在自然界中随处可见:

此外,许多现代设计师在他们的设计中使用黄金比例,最着名的是一些知名品牌的标志:
如果您有兴趣了解更多关于黄金分割的信息,您可以观看此视频。
Final Program
我们将为这个模块开发一个斐波那契序列计算器,它允许我们在学习各种汇编指令时练习它们,并在我们完成时构建程序,直到我们最终拥有完整的计算器程序。
该程序将首先询问您要计算的最大Fibonacci,然后打印所有Fibonacci数字。下面的例子向我们展示了它的外观:
mikannse7@htb[/htb]$ ./fib |
在本模块结束时,您将只使用汇编指令开发上述程序。我们可以从这个链接下载最终的程序并运行它来查看最终的项目结果。
Basic Instructions
Data Movement
让我们从数据移动指令开始,这是任何汇编程序中最基本的指令之一。我们将经常使用数据移动指令来在地址之间移动数据,在寄存器和内存地址之间移动数据,以及将立即数据加载到寄存器或内存地址中。主要的Data Movement指令是:
| Instruction | Description | Example |
|---|---|---|
mov |
移动数据或加载即时数据 | mov rax, 1 -> rax = 1 #1—>#2 |
lea |
加载指向值的地址 | lea rax, [rsp+5] -> rax = rsp+5 #1—>#2 |
xchg |
在两个寄存器或地址之间交换数据 | xchg rax, rbx -> rax = rbx, rbx = rax #1—>#2 |
Moving Data 移动数据
让我们使用mov指令作为模块项目fibonacci中的第一条指令。我们需要将初始值(F0=0和F1=1)加载到rax和rbx,这样rax = 0和rbx = 1。将下面的代码复制到fib.s文件中:
Code:
global _start |
现在,让我们汇编这段代码,并使用gdb运行它,看看mov指令是如何工作的:
gdb
$ ./assembler.sh fib.s -g |
像这样,我们已经将初始值加载到寄存器中,以便稍后对它们执行其他操作和指令。
注意:在汇编中,移动数据不影响源操作数.因此,我们可以将mov视为copy函数,而不是实际的移动。
Loading Data
我们可以使用mov指令加载立即数据。例如,我们可以使用1指令将rax的值加载到mov rax, 1寄存器中。在这里,我们要记住#5。例如,在上面的the size of the loaded data depends on the size of the destination register指令中,由于我们使用了64位寄存器mov rax, 1,因此它将移动数字rax的64位表示(即1),这不是很有效。
到与上述示例相同的结果,因为我们将1字节(0x01)移动到1字节寄存器(al)中,这要高效得多。当我们看一下objdump中两条指令的反汇编时,这一点很明显。
让我们拿下面的基本汇编代码来比较一下这两条指令的反汇编:
Code:
global _start |
现在让我们组装它并使用objdump查看它的shellcode:
mikannse7@htb[/htb]$ nasm -f elf64 fib.s && objdump -M intel -d fib.o |
我们可以看到第一条指令的shellcode是最后一条指令的两倍多。
This understanding will become very handy when writing shellcodes. |
让我们修改我们的代码,使用子寄存器来使其更有效:
Code:
global _start |
xchg指令将在两个寄存器之间交换数据。尝试将xchg rax, rbx添加到代码的末尾,组装它,然后通过gdb运行它,看看它是如何工作的。
Address Pointers
另一个需要理解的关键概念是使用指针。在许多情况下,我们会看到我们正在使用的寄存器或地址并不直接包含最终值,而是包含指向最终值的另一个地址。指针寄存器(如rsp、rbp和rip)总是如此,但也用于任何其他寄存器或内存地址。
例如,让我们在我们组装的gdb二进制文件上组装并运行fib,并检查rsp和rip寄存器:
gdb
gdb -q ./fib |
我们看到两个寄存器都包含指向其他位置的指针地址。GEF在向我们展示最终目标值方面做得很好。
Moving Pointer Values
我们可以看到,rsp寄存器保存0x1的最终值,其立即值是指向0x1的指针地址。因此,如果我们使用mov rax, rsp,我们不会将值0x1移动到rax,但我们会将指针地址0x00007fffffffe490移动到rax。
要移动实际值,我们必须使用方括号[],在x86_64汇编和Intel语法中表示load value at address。因此,在上面的例子中,如果我们想移动rsp指向的最终值,我们可以将rsp放在方括号中,就像mov rax, [rsp]一样,这个mov指令将移动最终值而不是立即值(这是最终值的地址)。
我们可以使用方括号来计算相对于寄存器或另一个地址的地址偏移。例如,我们可以做mov rax, [rsp+10]来将存储的值从rsp中移走。
为了正确地演示这一点,让我们采用以下示例代码:
Code:
global _start |
这只是一个简单的程序来演示这一点,看看这两个指令之间的区别。
现在,让我们汇编代码并使用gdb运行程序:
gdb
$ ./assembler.sh rsp.s -g |
正如我们所看到的,mov rax, rsp将存储在rsp的立即值(这是指向rsp的指针地址)移动到rax寄存器。现在让我们按下si并检查第二条指令后rax的外观:
gdb
$ ./assembler.sh rsp.s -g |
我们可以看到,这一次,0x1的最终值被移到了rax寄存器中。
注意:当使用[]时,我们可能需要在方括号前设置数据大小,如byte或qword。然而,在大多数情况下,nasm会自动为我们做这件事。我们可以从上面看到,最后一条指令实际上是mov rax, QWORD PTR [rsp]。我们还看到nasm还添加了PTR来指定从指针移动值。
Loading Value Pointers
最后,我们需要理解如何使用lea(或Load Effective Address)指令加载指向指定值的指针地址,如lea rax, [rsp]。这与我们刚刚学到的相反(即,将指针加载到值与从指针移动值)。
在某些情况下,我们需要将值的地址加载到某个寄存器中,而不是直接将值加载到该寄存器中。这通常是在数据很大并且不适合一个寄存器时完成的,因此数据被放置在堆栈或堆中,并且指向其位置的指针被存储在寄存器中。
例如,我们在write程序中使用的HelloWorld系统调用需要一个指向要打印的文本的指针,而不是直接提供文本,因为寄存器只有64位或8个字节,所以文本可能无法全部放入寄存器中。
首先,如果我们想加载一个指向变量或标签的直接指针,我们仍然可以使用mov指令。由于变量名是指向它在内存中的位置的指针,mov将存储指向目标地址的指针。例如,mov rax, rsp和lea rax, [rsp]都将做同样的事情,将指向message的指针存储在rax。
然而,如果我们想加载一个带有偏移量的指针(即,距离一个变量或一个地址几个地址),我们应该使用lea。这就是为什么在lea中,源操作数通常是一个变量、一个标签或一个用方括号括起来的地址,就像在lea rax, [rsp+10]中一样。这使得能够使用偏移(即,[rsp+10])。
请注意,如果我们使用mov rax, [rsp+10],它实际上会将[rsp+10]的值移动到rax,如前所述。我们不能使用mov移动带有偏移量的指针。
让我们以下面的例子来演示lea是如何工作的,以及它与mov有何不同:
Code:
global _start |
现在让我们组装它并使用gdb运行它:
gdb
$ ./assembler.sh lea.s -g |
我们看到lea rax, [rsp+10]加载了距离rsp10个地址的地址(换句话说,距离堆栈顶部10个地址)。现在让我们看看si会做什么:
gdb
─────────────────────────────────────────────────────────────────────────────────── code:x86:64 ──── |
正如预期的那样,我们看到mov rax, [rsp+10]将存储在那里的值移动到rax。
Arithmetic Instructions
第二类基本指令是算术指令。使用算术指令,我们可以对存储在寄存器和内存地址中的数据执行各种数学计算。这些指令通常由CPU中的ALU处理。我们将算术指令分为两种类型:只接受一个操作数的指令(Unary),接受两个操作数的指令(Binary)。
Unary Instructions
以下是主要的一元算术指令(我们假设每个指令的rax都是从1开始的):
| Instruction | Description | Example |
|---|---|---|
inc |
递增1 | inc rax -> rax++ or rax += 1 -> rax = 2 |
dec |
减1 | dec rax -> rax-- or rax -= 1 -> rax = 0 |
让我们回到我们的fib.s代码来练习这些指令。到目前为止,我们已经用初始值rax和rbx初始化了0和1,并使用mov指令。与其将1的立即值移动到bl,不如将0移动到它,然后使用inc使其成为1:
Code:
global _start |
请记住,我们使用al而不是rax来提高效率。现在,让我们组装代码,并使用gdb运行它:
$ ./assembler.sh fib.s -g |
正如我们所看到的,rbx以值0开始,而在inc rbx中,它被递增到1。dec指令类似于inc,但递减1而不是递增。
This knowledge will become very handy later on. |
Binary Instructions
接下来,我们有二进制算术指令,主要的是: 我们假设对于每个指令,rax和rbx都以1开始。
| Instruction | Description | Example |
|---|---|---|
add |
将两个操作数相加 | add rax, rbx -> rax = 1 + 1 -> 2 |
sub |
从目标中减去源(即rax = rax - rbx) |
sub rax, rbx -> rax = 1 - 1 -> 0 |
imul |
将两个操作数相乘 | imul rax, rbx -> rax = 1 * 1 -> 1 |
Note that in all of the above instructions, the result is always stored in the destination operand, while the source operand is not affected. |
让我们从讨论add指令开始。将两个数字相加是计算斐波那契数列的核心步骤,因为当前的斐波那契数(Fn)是前两个数字(Fn = Fn-1 + Fn-2)的和。
所以,让我们将add rax, rbx添加到fib.s代码的末尾:
Code:
global _start |
现在,让我们组装代码,并使用gdb运行它:
$ ./assembler.sh fib.s -g |
正如我们所看到的,在指令被处理之后,rax等于0x1 + 0x0,也就是0x1。使用相同的原理,如果我们在rax和rbx中有其他Fibonacci数,我们将使用add得到新的Fibonacci数。
sub和imul都类似于add,如前表中的示例所示。尝试将sub和imult添加到上述代码中,组装它,然后运行gdb以查看它们是如何工作的。
按位指令
现在,让我们转向位指令,这是在位级别上工作的指令(我们假设每个指令都有rax = 1和rbx = 2):
| Instruction | Description | Example |
|---|---|---|
not |
按位非(反转所有位,0->1和1->0) | not rax -> NOT 00000001 -> 11111110 |
and |
按位AND(如果两位都是1 -> 1,如果位不同-> 0) | and rax, rbx -> 00000001 AND 00000010 -> 00000000 |
or |
按位或(如果任一位为1 -> 1,如果两者均为0 -> 0) | or rax, rbx -> 00000001 OR 00000010 -> 00000011 |
xor |
按位XOR(如果位相同-> 0,如果位不同-> 1) | xor rax, rbx -> 00000001 XOR 00000010 -> 00000011 |
这些指令乍看起来可能令人困惑,但一旦我们理解它们,它们就很简单。这些指令中的每一个都对值的每一位执行指定的指令。例如,not将转到每个位并将其反转,将0转换为1,将1转换为0。尝试将not rax添加到我们前面的代码的末尾,组装它,然后使用gdb运行它,看看它是如何工作的。
同样,and/or指令都对每个位工作,并对每个位执行AND/OR门,如上面的示例所示。这些指令中的每一个都在程序集中有其用例。
但是,我们使用最多的指令是xor。xor指令有各种用例,但由于它将类似的位置零,我们可以使用它通过xoring一个值来将任何值变为0。我们需要把
例如,如果我们想将rax寄存器转换为0,最有效的方法是xor rax, rax,这将使rax = 0。这仅仅是因为rax的所有位都是相似的,所以xor将把它们全部转换为0。回到我们之前的fib.s代码,而不是将0移动到rax和rbx,我们可以在它们每个上使用xor,如下所示:
Code:
global _start |
这段代码应该执行完全相同的操作,但现在以更有效的方式。让我们组装代码,并使用gdb运行它:
$ ./assembler.sh fib.s -g |
正如我们所看到的,xoring我们的寄存器将它们中的每一个都变成了0的寄存器,其余的代码执行与前面相同的操作,所以我们最终得到了rax和rbx的相同的最终值。
Control Instructions
Loops
现在我们已经介绍了基本的说明,我们可以开始学习Program Control Instructions。正如我们已经知道的,汇编代码是基于行的,所以它总是会查看下面的行来处理指令。然而,正如我们所预料的那样,大多数程序并不遵循一组简单的顺序步骤,而是通常具有更复杂的结构。
这就是Control指令进来的地方。这样的指令允许我们改变程序的流程并将其引导到另一行。有许多例子可以说明如何做到这一点。我们已经讨论过Directives,它告诉程序将执行定向到特定的标签。
其他类型的Control Instructions包括:
Loops |
Branching |
Function Calls |
|---|---|---|
Loop Structure 环结构
让我们从#1开始讨论。汇编中的循环是一组重复Loops次的指令。让我们来看看下面的例子:
Code:
exampleLoop: |
一旦汇编代码到达exampleLoop,它将开始执行它下面的指令。我们应该在rcx寄存器中设置我们希望循环通过的迭代次数。每次循环到达loop指令时,它将rcx减少1(即,dec rcx)并跳回到指定的标签,在本例中为exampleLoop。因此,在我们进入任何循环之前,我们应该将mov循环迭代次数存入rcx寄存器。
| Instruction | Description | Example |
|---|---|---|
mov rcx, x |
将循环(rcx)计数器设置为x |
mov rcx, 3 |
loop |
跳回到loop的开头,直到计数器到达0 |
loop exampleLoop |
loopFib
为了证明这一点,让我们回到我们的fib.s代码:
Code:
global _start |
由于任何当前Fibonacci数都是它前面两个数字的总和,因此我们可以使用循环来自动执行此操作。假设当前的数字存储在rax中,所以它是Fn,下一个数字存储在rbx中,所以它是Fn+1。
从最后一个数字0和当前数字1开始,我们可以有如下循环:
- 使用
0 + 1 = 1获取下一个号码 - 将当前号码移动到最后一个号码(
1 in place of 0) - 将下一个数字移动到当前数字(
1 in place of 1) - Loop
如果我们这样做,我们最终将1作为最后一个数字,1作为当前数字。如果我们再次循环,我们将得到1作为最后一个数字,2作为当前数字。所以,让我们把它实现为汇编指令。由于我们可以在加法中使用最后一个数字0后丢弃它,让我们将结果存储在它的位置:
add rax, rbx
我们需要将当前数字移动到最后一个数字的位置,并将后面的数字移动到当前数字。然而,我们在rax中有以下数字,而在rbx中有现在的旧数字,所以它们被交换了。你能想到任何指令来交换它们吗?
让我们使用xchg指令来交换这两个数字:
xchg rax, rbx
现在我们可以简单地loop。然而,在我们进入循环之前,我们应该将rcx设置为我们想要的迭代次数。让我们从10迭代开始,并在初始化rax和rbx到0和1之后添加它:
Code:
_start: |
现在我们可以定义我们的循环,如上所述:
Code:
loopFib: |
所以,我们的最终代码是:
Code:
global _start |
Loop loopFib
让我们组装代码,并使用gdb运行它。我们将在b loopFib处中断,这样我们就可以在循环的每次迭代中检查代码。在第一次迭代之前,我们看到以下寄存器值:
gdb
$ ./assembler.sh fib.s -g |
我们从rax = 0和rbx = 1开始。让我们按下c继续下一次迭代:
gdb
───────────────────────────────────────────────────────────────────────────────────── registers ──── |
现在我们有了1和1,正如预期的那样,还有9次迭代。让我们ccontinue再次:
gdb
───────────────────────────────────────────────────────────────────────────────────── registers ──── |
现在我们在1和2。让我们检查接下来的三个迭代:
gdb
───────────────────────────────────────────────────────────────────────────────────── registers ──── |
正如我们所看到的,该脚本成功地计算出斐波那契数列为0, 1, 1, 2, 3, 5, 8。让我们继续最后一次迭代,其中rbx应该是55:
gdb
───────────────────────────────────────────────────────────────────────────────────── registers ──── |
我们看到rbx是0x37,在十进制中等于55。我们可以使用p/d $rax命令来确认:
gef➤ p/d $rbx |
正如我们所看到的,我们已经成功地使用循环来自动计算斐波那契数列。试着增加rcx,看看斐波那契数列中的下一个数字是什么。
Unconditional Branching
第二种类型的Control Instructions是Branching Instructions,这是一种通用指令,允许我们在满足特定条件的情况下将jump转移到程序中的任何一点。让我们首先讨论最基本的分支指令:jmp,它总是无条件地跳转到一个位置。
JMP loopFib
jmp指令将程序跳转到其操作数中的标签或指定位置,以便程序的执行在那里继续。一旦程序的执行被定向到另一个位置,它将继续处理来自该位置的指令。如果我们想暂时跳转到一个点,然后返回到原始调用点,我们将使用函数,我们将在下一节讨论。
基本的jmp指令是无条件的,这意味着它将总是跳转到指定的位置,而不管条件如何。这与仅在满足特定条件时才跳转的Conditional Branching指令形成对比,我们将在下面讨论。
| Instruction | Description | Example |
|---|---|---|
jmp |
跳转到指定的标签、地址或位置 | jmp loop |
让我们尝试在我们的jmp程序中使用fib.s,看看它会如何改变执行流。而不是循环回loopFib,让我们jmp代替: 所以,我们的最终代码是:
Code:
global _start |
现在,让我们组装代码,并使用gdb运行它。我们将再次b loopFib,看看它是如何变化的:
$ ./assembler.sh fib.s -g |
我们按几次c,让程序多次跳转到loopFib。正如我们所看到的,程序仍然在执行相同的功能,仍然正确地计算斐波那契序列。然而,the main difference from the loop is that 'rcx' is not decrementing.这是因为jmp指令不将rcx视为计数器(如loop),因此它不会自动递减它。
让我们用del 1删除断点,然后按下c看看程序会运行到哪一步:
gef➤ info break |
我们注意到,程序一直在运行,直到我们在几秒钟后按下ctrl+c杀死它,这时斐波那契数已经达到0x903b4b15ce8cedf0(这是一个巨大的数字)。这是因为无条件的jmp指令,它会一直跳回到loopFib,因为特定的条件不会限制它。这类似于(while true)循环。
这就是为什么无条件分支通常用于总是需要跳转的情况,它不适合循环,因为它将永远循环。为了在满足特定条件时停止跳转,我们将在接下来的步骤中使用Conditional Branching。
Conditional Branching
与无条件分支指令不同,Conditional Branching指令仅在满足特定条件时才根据目标和源操作数进行处理。条件跳转指令有多个变体,如Jcc,其中cc表示条件代码。以下是一些主要的条件代码:
| Instruction | Condition | Description |
|---|---|---|
jz |
D = 0 |
Destination equal to Zero |
jnz |
D != 0 |
Destination Not equal to Zero |
js |
D < 0 |
Destination is Negative |
jns |
D >= 0 |
Destination is Not Negative (i.e. 0 or positive) |
jg |
D > S |
Destination Greater than Source |
jge |
D >= S |
Destination Greater than or Equal Source |
jl |
D < S |
Destination Less than Source |
jle |
D <= S |
Destination Less than or Equal Source |
还有许多其他类似的条件,我们也可以利用。有关条件的完整列表,我们可以参考最新的Intelx86_64手册的 Jcc-Jump if Condition Is Met部分。条件指令不仅限于jmp指令,还可以与其他汇编指令一起用于条件使用,如CMOVcc和SETcc指令。
例如,如果我们想执行mov rax, rbx指令,但条件是= 0,那么我们可以使用CMOVcc或conditional mov指令,例如cmovz rax, rbx指令。类似地,如果我们想在条件是<的情况下移动,那么我们可以使用cmovl rax, rbx指令,对于其他条件依此类推。这同样适用于set指令,如果满足条件,则将操作数的字节设置为1,否则设置为0。这是一个例子。
RFLAGS Register
我们一直在谈论满足某些条件,但我们尚未讨论如何满足这些条件或将其存储在何处。这就是我们使用RFLAGS寄存器的地方,我们在寄存器一节中简要提到过。
与其他寄存器一样,RFLAGS寄存器由64位组成。但是,该寄存器不保存值,而是保存标志位。每个位或位组根据最后一条指令的值变为1或0。
Arithmetic instructions set the necessary 'RFLAG' bits depending on their outcome.例如,如果dec指令导致0,则位#6,即零标志ZF,变为1。同样地,每当比特#6为0时,这意味着零标志关闭。类似地,如果除法指令导致浮点数,则进位标志CF位被打开,或者如果sub指令导致负值,则符号标志SF被打开,等等。
注:当ZF打开时(即1),它被称为零ZR,当它关闭时(即0),它被称为非零NZ。这个命名可以匹配指令中使用的条件代码,比如jnz与NZ一起跳转。但为了避免任何混淆,让我们简单地关注旗帜名称。
在汇编程序中有许多标志,每个标志在RFLAGS寄存器中都有自己的位。下表显示了RFLAGS寄存器中的不同标志:
| Bit(s) | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12-13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22-63 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
Label (1/0) |
CF (CY/NC) CF(CY/NC) |
1 D > S |
PF (PE/PO) PF(PE/PO) |
0 D > S |
AF (AC/NA) AF(AC/NA) |
0 D > S |
ZF (ZR/NZ) ZF(ZR/NZ) |
SF (NC/PL) SF(NC/PL) |
TF D > S |
IF (EL/DI) IF(EL/DI) |
DF (DN/UP) DF(DN/UP) |
OF (OV/NV) OF(OV/NV) |
IOPL D > S |
NT D > S |
0 D > S |
RF D > S |
VM D > S |
AC D > S |
VIF D > S |
VIP D > S |
ID D > S |
0 D > S |
| Description | Carry Flag | Reserved | Parity Flag | Reserved | Auxiliary Carry Flag | Reserved | Zero Flag | Sign Flag | 陷阱标志 | 中断标志 | 方向标志 | 溢出标志 | 缓冲级别 | 嵌套任务 | 保留 | 重新开始标志 | 虚拟-x86模式 | 对齐检查/访问控制 | 虚拟机标志 | 虚拟主机挂起 | 识别旗标 | 保留 |
与其他寄存器一样,64位RFLAGS寄存器有一个32位子寄存器(称为EFLAGS)和一个16位子寄存器(称为FLAGS),它们保存我们可能遇到的最重要的标志。
我们最感兴趣的旗帜是:
- 进位标志
CF:表示我们是否有浮点数。 - 奇偶校验标志
PF:表示一个数字是奇数还是偶数。 - Zero Flag
ZF:表示一个数字是否为零。 - 符号标志
SF:表示寄存器是否为负。
上述所有标志都位于FLAGS子寄存器的前几位。我们将只在模块项目中使用jnz指令,只要ZF标志等于0(即,非零NZ)。那么,让我们看看如何做到这一点。
JNZ loopFib
我们在上一节中使用的loop loopFib指令实际上是两个指令的组合:dec rcx和jnz loopFib,但由于循环是一个非常常见的功能,因此创建loop指令是为了减少代码大小并提高效率,而不是每次都使用这两个指令。然而,条件跳转指令比loop通用得多,因为它们允许我们在任何我们需要的条件下跳转到程序中的任何地方。
虽然使用loop更有效,但为了演示jnz的使用,让我们回到我们的代码,尝试使用jnz指令而不是loop:
Code:
global _start |
我们看到我们用loop loopFib和dec rcx替换了jnz loopFib,这样每次循环结束时,rcx计数器将减1,如果没有设置loopFib,程序将跳回到ZF。一旦rcx到达0,零标志ZF将被打开到1,因此jnz将不再跳转(因为它是NZ),我们将退出循环。让我们组装代码,并使用gdb运行它,看看效果如何:
$ ./assembler.sh fib.s -g |
我们可以看到,我们仍然正确地计算斐波那契序列。在循环的每次迭代中,我们减少rcx,并且zero标志关闭,而当parity是奇数时,rcx标志打开。此时RFLAGS的值是在dec rcx指令之后设置的,因为这是我们中断之前的最后一条算术指令。所以,旗国是rcx。
注:GEF显示了RFLAGS寄存器中标志的状态。以粗体大写字母书写的标志处于打开状态。
让我们c继续跳出循环,看看rcx到达0后寄存器和RFLAGS的状态:
gef➤ |
我们看到,一旦rcx到达0,zero标志就被设置为on 1,而jnz不再跳回到loopFib,因此程序停止执行。
CMP
在其他情况下,我们可能希望在模块项目中使用条件跳转指令。例如,我们可能希望在斐波那契数大于10时停止程序执行。我们可以通过使用js loopFib指令来实现这一点,只要最后一条算术指令的结果是正数,它就会跳回到loopFib。
在这种情况下,我们将不使用jnz指令或rcx寄存器,而是在计算当前Fibonacci数后直接使用js。但是我们如何测试当前的斐波那契数(即,rbx)小于10?这就是我们来到比较指令cmp。
比较指令cmp通过从第一操作数中减去第二操作数(即D1 - S2)来简单地比较两个操作数,然后在RFLAGS寄存器中设置必要的标志。例如,如果我们使用cmp rbx, 10,那么比较指令将执行“rbx - 10”,并根据结果设置标志。
| Instruction | Description | Example |
|---|---|---|
cmp D > S |
通过从第一个操作数中减去第二个操作数来设置RFLAGS(即第一-第二) |
cmp rax, rbx -> rax - rbx |
因此,在计算第一个斐波那契数之后,它将执行’1 - 10‘,结果将是-9,因此它将跳转,因为它是负数<0。一旦我们到达第一个大于10的斐波那契数,即13或0xd,它将执行“13 - 10”,结果将是“3”,在这种情况下js将不再跳跃,因为结果是正数>=0。
我们可以使用sub指令来执行相同的减法,并根据需要设置标志。然而,这并不有效,因为我们将更改其中一个寄存器的值,而cmp只进行比较,并不将结果存储在任何地方。The main advantage of 'cmp' is that it does not affect the operands.
注意:在cmp指令中,第一个操作数(即目的地)必须是寄存器,而另一个可以是寄存器,变量或立即值。
因此,让我们将代码更改为使用cmp和js,如下所示:
Code:
global _start |
请注意,我们删除了mov rcx, 10指令,因为我们不再使用rcx循环。我们可以在cmp中使用它而不是10,但是通过直接使用10,我们少用了一条指令,使我们的代码更短,更高效。
现在,让我们组装代码,并使用gdb运行它,看看这是如何工作的。我们将在loopFib处中断,然后执行si,直到到达js loopFib指令:
$ ./assembler.sh fib.s -g |
我们看到,在loopFib的第一次迭代中,一旦我们到达js loopFib,SIGN标志就像预期的那样被设置为1,因为1 - 10的结果是负数。我们还注意到GEF告诉我们TAKEN [Reason: S],这很方便地告诉我们将进行此条件跳转,并给出原因为S,这意味着设置了SIGN标志。
现在,让我们c继续,直到rbx大于10,在这一点上js应该不再跳。与其手动多次按下c,不如借此机会学习如何在gdb中设置条件断点。
让我们先用del 1删除当前断点,然后设置条件断点。语法与设置常规断点b loopFib非常相似,但我们在它后面添加了一个if条件,例如’b loopFib if $rbx > 10‘。此外,与其在loopFib处中断然后使用si到达js,不如直接在js处中断,使用*来引用其位置’b *loopFib+9 if $rbx > 10‘或’b *0x401012 if $rbx > 10‘。
记住:我们可以通过disas loopFib找到指令的位置。
我们看到以下情况:
gef➤ del 1 |
我们现在看到,最后一个算术指令’13 - 10‘的结果是一个正数,sign标志不再被设置,所以GEF告诉我们,这个跳转是NOT TAKEN,原因是!(S),这意味着sign标志没有被设置。
正如我们所看到的,使用条件分支非常强大,使我们能够根据指定的条件执行更高级的指令。我们可以使用cmp指令来测试各种条件。例如,我们可以使用jl而不是jns,只要目标小于源,它就会跳转。因此,对于cmp rbx, 10,rbx将开始小于10,并且一旦rbx大于10,则rbx(即,目的地)将大于10,在该点jl将不跳转。
注意:我们可能会看到使用JMP Equal je或JMP Not Equal jne的指令。这只是jz和jnz的别名,因为如果两个操作数相等,则在所有情况下cmp rax, rax的结果都将是0,这设置了零标志。这同样适用于jge和jnl,因为>=与!相同,并且也适用于其他类似的条件。
现在我们已经介绍了所有基本的控制指令,您认为哪种方法更有效?
- 使用
mov rcx, 10和loop loopFib=循环10次 - 使用
mov rcx, 10、dec rcx和jnz loopFib=跳转10次 - 使用
cmp rbx, 10和js loopFib= jump while rbx 10
修改你的代码,使用你认为最好的方法。
Functions
Using the Stack
到目前为止,我们已经学习了两种类型的控制指令:Loops和Branching。在我们讨论Functions之前,我们需要了解如何使用内存Stack。在第5节中,我们讨论了如何将RAM划分为四个不同的段,并为每个应用程序分配其虚拟内存及其段。我们还讨论了用于加载应用程序的汇编指令以供CPU访问的Computer Architecture段,以及用于保存应用程序变量的text段。所以,现在让我们开始讨论data。
The Stack
堆栈是分配给程序存储数据的内存段,通常用于存储数据,然后临时取回数据。堆栈的顶部由顶部堆栈指针rsp引用,而底部由底部堆栈指针rbp引用。
我们可以将push数据放入堆栈,它将位于堆栈的顶部(即rsp),然后我们可以将pop数据从堆栈中取出,放入寄存器或内存地址,它将从堆栈顶部移除。
| Instruction | Description | Example |
|---|---|---|
push |
Copies the specified register/address to the top of the stack | push rax |
pop |
Moves the item at the top of the stack to the specified register/address将堆栈顶部的项移动到指定的寄存器/地址 | pop rax |
堆栈有一个Last-in First-out(LIFO)设计,这意味着我们只能pop出最后一个元素pushed到堆栈。例如,如果我们将push rax放入堆栈,那么堆栈的顶部现在将是我们刚刚推入的rax的值。如果我们push在它上面的任何东西,我们将不得不pop它们从堆栈中出来,直到rax的值到达堆栈的顶部,然后我们可以pop该值返回到rax。
Usage With Functions/Syscalls
在调用function或syscall之前,我们将主要将数据从寄存器推入堆栈,然后在函数和系统调用之后恢复它们。这是因为functions和syscalls通常使用寄存器进行处理,因此如果存储在寄存器中的值在函数调用或系统调用后发生更改,我们将丢失它们。
例如,如果我们想调用一个系统调用来将Hello World打印到屏幕上,并保留存储在rax中的当前值,我们将push rax放入堆栈。然后我们可以执行syscall,然后pop将值返回到rax。所以,这样,我们就可以执行syscall并保留rax的值。
PUSH/POP
我们的代码目前看起来如下:
Code:
global _start |
让我们假设我们想在进入循环之前调用function或syscall。为了保留我们的寄存器,我们将需要push到堆栈中所有我们正在使用的寄存器,然后在syscall之后将它们弹出。
要将push值放入栈中,我们可以使用其名称作为操作数,如push rax中所示,而该值将copied放入栈顶。当我们想要检索该值时,我们首先需要确保它位于堆栈顶部,然后我们可以指定存储位置作为操作数,如pop rax,之后值将是moved到rax,并且将是堆栈顶部的removed。它下面的值现在将位于堆栈的顶部(如上面的附加工作所示)。
由于堆栈具有LIFO设计,当我们恢复寄存器时,我们必须以相反的顺序进行。例如,如果我们先推rax,然后推rbx,当我们恢复时,我们必须先弹出rbx,然后再弹出rax。
因此,为了在进入循环之前保存寄存器,让我们将它们推到寄存器。幸运的是,我们只使用了rax和rbx,所以我们只需要将这两个寄存器添加到堆栈中,然后在系统调用之后添加到堆栈中,如下所示:
global _start |
请注意,使用pop恢复寄存器的顺序是相反的。
现在,让我们组装我们的代码并使用gdb进行测试:
$ ./assembler.sh fib.s -g |
我们看到,在执行push rax之前,我们有rax = 0x0和rbx = 0x1。现在让我们push``rax和rbx,看看堆栈和寄存器是如何变化的:
───────────────────────────────────────────────────────────────────────────────────── registers ──── |
我们看到,在我们对push和rax都进行了rbxed之后,我们在堆栈顶部有以下值:
0x00007fffffffe408│+0x0000: 0x0000000000000001 ← $rsp |
我们可以看到,在堆栈的顶部,我们有我们推送的最后一个值,即rbx = 0x1,就在它下面,我们有我们推送的值rax = 0x0。这和我们预期的一样,与上面的堆栈练习类似。我们还注意到,在我们推送我们的值之后,它们仍然留在寄存器中,meaning a push is, in fact, a copy to stack。
现在假设我们完成了一个print函数的执行,并且想要取回我们的值,所以我们继续执行pop指令:
───────────────────────────────────────────────────────────────────────────────────── registers ──── |
我们看到,在从堆栈顶部poping两个值之后,它们被从堆栈中删除,现在堆栈看起来和我们第一次开始时完全一样。这两个值都被放回rbx和rax。我们可能没有看到任何差异,因为在这种情况下,它们在登记册中没有改变。
使用堆栈非常简单。我们应该记住的唯一一件事是我们推送寄存器的顺序和堆栈的状态,以安全地恢复我们的数据,并且当不同的值位于堆栈顶部时,不会在pop之前恢复不同的值。
我们现在可以从代码中删除push和pop指令,我们将在进入函数调用时使用它们。这样,我们就可以使用syscall和function调用了。接下来让我们讨论syscalls。
Syscalls
即使我们在汇编中通过机器指令直接与CPU对话,我们也不必只使用基本的机器指令来调用每一种类型的命令。程序通常使用多种操作。操作系统可以通过系统调用帮助我们不必每次手动执行这些操作。
例如,假设我们需要在屏幕上写一些东西,而不使用系统调用。在这种情况下,我们需要与视频内存和视频I/O对话,解决任何需要的编码,发送要打印的输入,并等待确认它已被打印。正如预期的那样,如果我们不得不做所有这些来打印一个字符,这将使汇编代码更长。
Linux Syscall
syscall就像是用C编写的一个全局可用的函数,由操作系统内核提供。系统调用在寄存器中获取所需的参数,并使用提供的参数执行函数。例如,如果我们想在屏幕上写一些东西,我们可以使用write系统调用,提供要打印的字符串和其他必需的参数,然后调用系统调用来发出打印。
Linux内核提供了许多可用的系统调用,我们可以通过阅读syscall number系统文件找到它们的列表和每个系统调用的unistd_64.h:
mikannse7@htb[/htb]$ cat /usr/include/x86_64-linux-gnu/asm/unistd_64.h |
上面的文件为每个系统调用设置系统调用编号,以使用此编号引用该系统调用。
注:对于32-bit x86处理器,系统调用编号位于unistd_32.h文件中。
让我们通过打印到屏幕的write系统调用来练习使用系统调用。我们还不会打印斐波那契数,而是在程序开始时打印一条介绍消息Fibonacci Sequence。
Syscall Function Arguments
要使用write系统调用,我们必须首先知道它接受什么参数。要查找系统调用接受的参数,我们可以使用上面列表中的带有系统调用名称的man -s 2命令:
mikannse7@htb[/htb]$ man -s 2 write |
从上面的输出中我们可以看到,write函数的语法如下:
Code:
ssize_t write(int fd, const void *buf, size_t count); |
我们看到syscall函数需要3个参数:
- 要打印到的文件描述符
fd(通常为1的stdout) - 指向要打印的字符串的地址指针
- 我们要打印的长度
一旦我们提供了这些参数,我们就可以使用syscall指令来执行函数并打印到屏幕。除了这些手动定位系统调用和函数参数的方法外,我们还可以使用在线资源来快速查找系统调用、它们的编号以及它们所期望的参数,如此表。此外,我们可以随时参考Github上的Linux源代码。
提示:-s 2标志指定syscall手册页。我们可以检查man man以查看每个手册页的各个部分。
Syscall Calling Convention
现在我们已经了解了如何定位各种系统调用及其参数,让我们开始学习如何调用它们。要调用系统调用,我们必须:
- 将寄存器保存到堆栈
- 在
rax中设置其系统调用编号 - 在寄存器中设置其参数
- 使用syscall汇编指令调用它
We usually should save any registers we use to the stack before any function call or syscall.然而,由于我们在使用任何寄存器之前在程序开始时运行此系统调用,因此寄存器中没有任何值,因此我们不应该担心保存它们。
我们将讨论保存寄存器到堆栈中,当我们到达Function Calls。
Syscall Number
让我们从将系统调用号移动到rax寄存器开始。正如我们前面看到的,write系统调用有一个编号1,所以我们可以从以下命令开始:
Code:
mov rax, 1 |
现在,如果我们到达syscall指令,内核将知道我们正在调用哪个syscall。
Syscall Arguments
接下来,我们应该把每个函数的参数放在相应的寄存器中。x86_64架构的调用约定指定每个参数应该放在哪个寄存器中(例如,第一个arg应该在rdi中)。所有函数和系统调用都应该遵循这个标准,并从相应的寄存器中获取参数。我们在第3节中讨论了下表:
| Description | 64-bit Register | 8-bit Register |
|---|---|---|
| Syscall Number/Return value | rax |
al |
| Callee Saved | rbx |
bl |
| 1st arg | rdi |
dil |
| 2nd arg | rsi |
sil |
| 3rd arg | rdx |
cl |
| 4th arg | rcx |
bpl |
| 5th arg | r8 |
r8b |
| 6th arg | r9 |
r9b |
正如我们所看到的,我们为每个前6参数都有一个寄存器。任何额外的参数都可以存储在堆栈中(尽管没有多少系统调用使用超过6的参数)。
注意:rax也用于存储系统调用或函数的return value。所以,如果我们期望从syscall/函数中获取一个值,它将在rax中。
这样,我们就应该知道我们的论点,以及我们应该把它们存储在哪个寄存器中。回到write syscall函数,我们应该传递:fd,pointer和length。我们可以这样做:
rdi-1(用于标准输出)rsi-'Fibonacci Sequence:\n'(指向我们的字符串的指针)rdx-20(字符串的长度)
我们可以使用mov rcx, string。然而,我们只能在寄存器中存储最多16个字符(即,64位),所以我们的介绍字符串不适合。相反,让我们用我们的字符串创建一个变量(正如我们在mov rcx, 'string'部分中所学到的那样),类似于我们对Assembly File Structure程序所做的:
Code:
global _start |
注意我们是如何在字符串后面添加0x0a来添加一个新的行字符的。
message标签是一个指针,指向我们的字符串将存储在内存中的位置。我们可以把它作为第二个论据。因此,我们的最终syscall代码应该如下所示:
Code:
mov rax, 1 ; rax: syscall number 1 |
提示:如果我们需要创建一个指向寄存器中存储的值的指针,我们可以简单地将其推送到堆栈,然后使用rsp指针指向它。
我们也可以通过使用length来使用动态计算的equ变量,类似于我们对Hello World程序所做的。
Calling Syscall
现在我们已经有了syscall编号和参数,剩下的唯一事情就是执行syscall指令。因此,让我们添加一个syscall指令,并将这些指令添加到我们的fib.s代码的开头,它应该看起来如下所示:
Code:
global _start |
现在让我们组装代码并运行它,看看我们的介绍消息是否被打印出来:
mikannse7@htb[/htb]$ ./assembler.sh fib.s |
我们看到字符串确实被打印到了屏幕上。让我们通过gdb运行它,并在syscall处中断,以查看在调用syscall之前如何设置所有参数,如下所示:
$ gdb -q ./fib |
我们看到了一些我们预期的事情:
- 我们的参数在每次系统调用之前都在相应的寄存器中正确设置。
- 指向我们的消息的指针加载在
rsi中。
现在,我们已经成功地使用了write系统调用来打印我们的介绍消息。
退出系统调用
最后,既然我们已经了解了系统调用的工作原理,让我们来看看程序中使用的另一个基本系统调用:Exit syscall。我们可能已经注意到,到目前为止,每当我们的程序完成执行时,它都会以segmentation fault退出,正如我们刚刚在运行./fib时看到的那样。这是因为我们突然结束了我们的程序,而没有通过调用exit syscall并传递退出代码来退出Linux中的程序。
所以,让我们把它添加到代码的末尾。首先,我们需要找到exit syscall号,如下所示:
mikannse7@htb[/htb]$ grep exit /usr/include/x86_64-linux-gnu/asm/unistd_64.h |
我们需要使用第一个,使用syscall编号60。接下来,让我们看看exit syscall是否需要任何参数:
mikannse7@htb[/htb]$ man -s 2 exit |
我们看到它只需要一个整数参数,status,它被解释为退出代码。在Linux中,每当程序退出而没有任何错误时,它都会传递退出代码0。否则,退出代码是不同的数字,通常是1。在我们的例子中,由于一切都按预期进行,我们将传递退出代码0。我们的exit syscall代码应该如下所示:
Code:
mov rax, 60 |
现在,让我们将它添加到代码的末尾:
Code:
global _start |
现在我们可以汇编代码并重新编译:
mikannse7@htb[/htb]$ ./assembler.sh fib.s |
好极了!我们看到,这次我们的程序正确退出,没有使用segmentation fault。我们可以检查传递的退出代码如下:
mikannse7@htb[/htb]$ echo $? |
正如我们在系统调用中指定的那样,退出代码是0。
练习:要完全掌握系统调用的工作原理,请尝试实现write系统调用来打印Fibonacci数,并将其放在’xchg rax, rbx‘之后。
Spoiler:它不会工作。尝试找出原因,并尝试修复它以打印10以下的前几个斐波那契数字(提示:使用ASCII)。
Procedures
随着代码复杂性的增加,我们需要开始重构代码,以更有效地使用指令,并使其更容易阅读和理解。一种常见的方法是使用functions和procedures。虽然函数需要一个调用过程来调用它们并传递它们的参数(我们将在下一节中讨论),但procedures通常更直接,主要用于代码重构。
procedure(有时称为subroutine)通常是我们希望在程序中的特定点执行的一组指令。因此,我们不是重用相同的代码,而是将其定义在过程标签下,并在需要使用它时使用它。这样,我们只需要编写一次代码,但可以多次使用它。此外,我们可以使用过程将更大更复杂的代码分割成更小更简单的部分。
让我们回到我们的代码:
Code:
global _start |
我们看到我们现在在一大块代码中做了很多事情:
- 打印介绍消息
- 将初始Fibonacci值设置为
0和1 - 使用循环计算以下斐波那契数
- 退出程序
我们的循环已经定义在标签下,所以我们可以在需要的时候调用它。然而,代码的其他三部分可以重构为过程,以便在需要的时候调用它们,从而提高代码效率。
Defining Procedures
作为一个起点,让我们在我们想要转换为过程的代码的三个部分中的每一个上面添加一个标签:
Code:
global _start |
我们看到我们的代码已经看起来更好了。然而,这并没有比以前更有效,因为我们可以通过使用注释来实现同样的效果。因此,我们的下一步是使用calls将程序定向到我们的每个过程。
CALL/RET
当我们想开始执行一个过程时,我们可以call它,它将通过它的指令。call指令推送(即,保存)下一个指令指针rip到堆栈,然后跳转到指定的过程。
一旦过程被执行,我们应该用一个ret指令结束它,以返回到跳到过程之前的位置。ret指令pops将堆栈顶部的地址转换为rip,因此程序的下一条指令将恢复到跳转到该过程之前的状态。
ret指令在面向返回的编程(ROP)中起着至关重要的作用,ROP是一种通常与二进制开发一起使用的开发技术。
| Instruction | Description | Example |
|---|---|---|
call |
将下一个指令指针rip压入堆栈,然后跳转到指定的过程 |
call printMessage |
ret |
将rsp的地址弹出到rip,然后跳转到它 |
ret |
因此,我们可以在代码的开头设置调用,以定义我们想要的执行流:
Code:
global _start |
这样,我们的代码应该像以前一样执行相同的指令,同时让我们的代码更干净,更高效。从现在开始,如果我们需要编辑一个特定的过程,我们将不必显示整个代码,而只需显示该过程。我们还可以看到,我们没有在我们的ret过程中使用Exit,因为我们不想回到我们原来的位置。我们想退出代码。我们几乎总是使用ret,而Exit函数是少数例外之一。
注意:理解装配的基于行的执行流很重要。如果我们在一个过程的末尾不使用ret,它将简单地执行下一行。同样,如果我们在Exit函数的末尾返回,我们将简单地返回并执行下一行,这将是printMessage的第一行。
最后,我们还应该提到enter和leave指令,它们有时与过程一起使用,以保存和恢复rsp和rbp的地址,并分配特定的堆栈空间供过程使用。但是,我们不需要在本模块中使用它们。
Functions
我们现在应该理解用于控制程序执行流的不同分支和控制指令。我们还应该正确掌握过程和调用,以及如何将它们用于分支。所以,现在让我们专注于调用函数。
Functions Calling Convention
函数是procedures的一种形式。然而,函数往往更复杂,应该完全使用堆栈和所有寄存器。因此,我们不能像调用过程那样简单地调用函数。相反,函数在被调用之前有一个Calling Convention来正确设置。
在调用一个函数之前,我们需要考虑四个主要的事情:
Save Registers在堆栈上(Caller Saved)- 通过
Function Arguments(如系统调用) - 修复
Stack Alignment - 获取函数的
Return Value(在rax中)
这与调用syscall相对类似,与syscall的唯一区别是我们必须将syscall编号存储在rax中,而我们可以直接使用call function调用函数。此外,使用syscall我们不必担心Stack Alignment。
Writing Functions
上面所有的观点都是从caller的角度来看的,因为我们称之为函数。当涉及到编写函数时,有不同的点需要考虑,它们是:
- 保存
Callee Saved寄存器(rbx和rbp) - 从寄存器获取参数
- Align the Stack对齐堆栈
- 返回
rax中的值
正如我们所看到的,这些点与caller点相对相似。caller是设置的东西,然后callee(即,接收器)应该检索这些东西并使用它们。这些点通常在函数的开始和结束处,称为函数的prologue和epilogue。它们允许调用函数而不用担心堆栈或寄存器的当前状态。
In this module, we will only be calling other functions,所以我们只需要专注于设置函数调用,而不会去写函数。
Using External Functions
我们希望在loopFib循环的每次迭代中打印当前Fibonacci数。以前,我们不能使用write系统调用,因为它只接受ASCII字符。我们必须将斐波那契数转换为ASCII,这有点复杂。
幸运的是,我们可以使用外部函数来打印当前数字,而无需转换它。用于libc程序的C函数库提供了许多功能,我们可以使用这些功能,而无需从头开始重写所有内容。printf中的libc函数接受打印格式,因此我们可以将当前Fibonacci数传递给它,并告诉它将其打印为整数,它将自动进行转换。在使用libc中的函数之前,我们必须先导入它,然后在将代码与libc链接时指定ld库进行动态链接。
Importing libc
首先,要导入外部libc函数,我们可以在代码的开头使用extern指令,如下所示:
Code:
global _start |
完成后,我们应该能够调用printf函数。所以,我们可以继续前面讨论的#2。
Saving Registers
让我们定义一个新的过程printFib来保存我们的函数调用指令。第一步是保存我们正在使用的任何寄存器,即rax和rbx,如下所示:
Code:
printFib: |
因此,我们可以继续第二点,并将所需的参数传递给printf。
Function Arguments
我们已经在系统调用一节中讨论了如何传递函数参数。同样的过程也适用于函数参数。
首先,我们需要通过对printf使用man -s 3来找出library functions manual函数接受哪些参数(正如我们在man man中看到的那样):
mikannse7@htb[/htb]$ man -s 3 printf |
正如我们所看到的,该函数接受一个指向打印格式的指针(用*表示),然后是要打印的字符串。
首先,我们可以创建一个包含输出格式的变量,将其作为第一个参数传递。1#手册页还详细介绍了各种打印格式。我们想打印一个整数,所以我们可以使用printf格式,如下所示:
Code:
global _start |
注意:我们以空字符0x00结束格式,因为这是printf中的字符串终止符,我们必须用它来终止任何字符串。
这可以是我们的第一个参数,rbx作为我们的第二个参数,printf将放置为%d。因此,让我们将两个参数移动到它们各自的寄存器,如下所示:
Code:
printFib: |
Stack Alignment
每当我们想对一个函数做一个call时,我们必须确保Top Stack Pointer (rsp)与16-byte函数堆栈中的_start边界对齐。
这意味着我们必须在调用之前将至少16个字节(或16个字节的倍数)压入堆栈,以确保函数有足够的堆栈空间来正确执行。这一要求主要是为了处理器的性能效率。有些函数(如libc中)被编程为在边界不固定时崩溃,以确保性能效率。如果我们组装代码,并在第二个push之后立即中断,这就是我们将看到的:
───────────────────────────────────────────────────────────────────────────────────────── stack ──── |
我们看到有4个8字节的数据被压入堆栈,总共有32字节。这是由于两件事:
- 每个过程
call向堆栈添加一个8字节的地址,然后用ret删除该地址 - 每个
push也向堆栈添加8个字节
因此,我们在printFib和loopFib中,并且已经推送了rax和rbx,总共有32字节的边界。由于边界是16的倍数,因此our stack is already aligned, and we don't have to fix anything.
如果我们想要将边界增加到16,我们可以从rsp中减去字节,如下所示:
Code:
sub rsp, 16 |
通过这种方式,我们将额外的16个字节添加到堆栈顶部,然后在调用后删除它们。如果我们有8个字节被压入,我们可以通过从rsp中减去8来将边界提高到16。
这可能有点令人困惑,但要记住的关键是we should have 16-bytes (or a multiple of 16) on top of the stack before making a call.我们可以计算(unpoped)push指令和(unreturned)call指令的数量,我们将得到有多少个8字节被推入堆栈。
Function Call
最后,我们可以发出call printf,它应该以我们指定的格式打印当前Fibonacci数,如下所示:
Code:
printFib: |
现在我们应该准备好我们的printFib程序了。因此,我们可以将它添加到loopFib的开头,这样它就可以在每个循环的开头打印当前的斐波那契数:
Code:
loopFib: |
我们的最终fib.s代码应该如下所示:
Code:
global _start |
Dynamic Linker
我们现在可以用nasm来组装代码。当我们使用ld链接代码时,我们应该告诉它使用libc库进行动态链接。否则,它将不知道如何获取导入的printf函数。我们可以使用-lc --dynamic-linker /lib64/ld-linux-x86-64.so.2标志来实现,如下所示:
mikannse7@htb[/htb]$ nasm -f elf64 fib.s && ld fib.o -o fib -lc --dynamic-linker /lib64/ld-linux-x86-64.so.2 && ./fib |
正如我们所看到的,printf使得打印Fibonacci数变得非常容易,而不必担心将其转换为正确的格式,就像我们必须使用write系统调用一样。接下来,我们需要通过另一个使用外部libc函数的例子来理解如何正确调用外部函数。
Libc Functions
到目前为止,我们只打印了小于10的Fibonacci数。但这样,我们的程序是静态的,每次都打印相同的输出。为了使它更动态,我们可以要求用户输入他们想要打印的最大Fibonacci数,然后使用cmp。在我们开始之前,让我们回顾一下函数调用约定:
Save Registerson the Stack(Caller Saved)- 通过
Function Arguments(如系统调用) - 修复
Stack Alignment - 获取函数的
Return Value(在rax中)
所以,让我们导入我们的函数,并从调用约定步骤开始。
Importing libc Functions
为此,我们可以使用scanf中的libc函数来获取用户输入,并将其正确转换为整数,稍后我们将使用cmp。首先,我们必须导入scanf,如下所示:
Code:
global _start |
我们现在可以开始编写一个新的过程getInput,这样我们就可以在需要的时候调用它:
Code:
getInput: |
Saving Registers
由于我们正处于程序的开始阶段,还没有使用任何寄存器,所以我们不必担心将寄存器保存到堆栈中。因此,我们可以继续第二点,并将所需的参数传递给scanf。
Function Arguments
接下来,我们需要知道scanf接受哪些参数,如下所示:
mikannse7@htb[/htb]$ man -s 3 scanf |
我们看到,与printf类似,scanf接受一个输入格式和我们希望保存用户输入的缓冲区。所以,让我们首先添加inFormat变量:
Code:
section .data |
我们还将介绍消息从Fibonacci Sequence:更改为Please input max Fn,以告诉用户期望他们输入什么。
接下来,我们必须为输入存储器设置一个缓冲空间。正如我们在Processor Architecture部分中提到的,未初始化的缓冲区空间必须存储在.bss内存段中。因此,在我们的汇编代码开始时,我们必须将其添加到.bss标签下,并使用resb 1告诉nasm保留1字节的缓冲区空间,如下所示:
Code:
section .bss |
现在我们可以在getInput过程下设置函数参数:
Code:
getInput: |
Stack Alignment
接下来,我们必须确保16字节的边界对齐我们的堆栈。我们目前在getInput过程中,所以我们有1个call指令,没有push指令,所以我们有一个8-byte边界。因此,我们可以使用sub来修复rsp,如下所示:
Code:
getInput: |
我们可以push rax代替,这也会正确对齐堆栈。这样,我们的堆栈应该与16字节的边界完美对齐。
Function Call
现在,我们设置函数参数和call scanf,如下所示:
Code:
getInput: |
我们还将在call getInput处添加_start,以便在打印介绍消息后立即执行此过程,如下所示:
Code:
section .text |
最后,我们必须利用用户输入。为此,在10中进行比较时,我们将其更改为cmp rbx, 10,而不是使用静态cmp rbx, [userInput],如下所示:
Code:
loopFib: |
注意:我们使用[userInput]而不是userInput,因为我们想与最终值进行比较,而不是与指针地址进行比较。
完成所有这些之后,我们最终的完整代码应该如下所示:
Code:
global _start |
Dynamic Linker
让我们组装代码,链接它,并尝试打印Fibonacci数直到100:
mikannse7@htb[/htb]$ nasm -f elf64 fib.s && ld fib.o -o fib -lc --dynamic-linker /lib64/ld-linux-x86-64.so.2 && ./fib |
我们看到我们的代码如预期的那样工作,并且打印的Fibonacci数小于我们指定的数字。有了这个,我们就可以完成我们的模块项目,并创建一个程序,根据我们提供的输入计算和打印斐波那契数,只使用汇编。
此外,我们需要学习如何将汇编代码转换为机器外壳代码,然后我们可以直接在二进制开发中的有效负载中使用。